








You are here:
AI accelerator (NPU) IP - 16 to 32 TOPS
The Origin E6 is a versatile NPU that is customized to match the needs of next-generation smartphones, automobiles, AV/VR, and consumer devices. With support for video, audio, and text-based AI networks, including standard, custom, and proprietary networks, the E6 is the ideal hardware/software co-designed platform for chip architects and AI developers. It offers broad native support for current and emerging AI models, and achieves ultra-efficient workload scheduling and memory management, with up to 90% processor utilization—avoiding dark silicon waste.
The Origin E6 neural engine uses Expedera’s unique packet-based architecture, which is far more efficient than common layer-based architectures. The architecture enables parallel execution across multiple layers achieving better resource utilization and deterministic performance. It also eliminates the need for hardware-specific optimizations, allowing customers to run their trained neural networks unchanged without reducing model accuracy. This innovative approach greatly increases performance while lowering power, area, and latency.
The Origin E6 neural engine uses Expedera’s unique packet-based architecture, which is far more efficient than common layer-based architectures. The architecture enables parallel execution across multiple layers achieving better resource utilization and deterministic performance. It also eliminates the need for hardware-specific optimizations, allowing customers to run their trained neural networks unchanged without reducing model accuracy. This innovative approach greatly increases performance while lowering power, area, and latency.
View AI accelerator (NPU) IP - 16 to 32 TOPS full description to...
- see the entire AI accelerator (NPU) IP - 16 to 32 TOPS datasheet
- get in contact with AI accelerator (NPU) IP - 16 to 32 TOPS Supplier
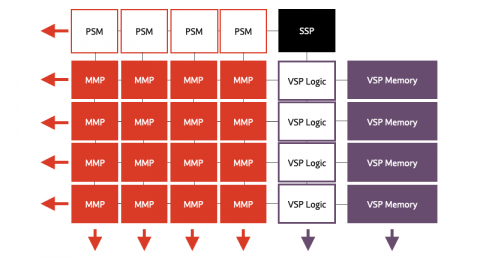
Block Diagram of the AI accelerator (NPU) IP - 16 to 32 TOPS

AI accelerator IP
- AI accelerator (NPU) IP - 1 to 20 TOPS
- AI accelerator (NPU) IP - 32 to 128 TOPS
- Deeply Embedded AI Accelerator for Microcontrollers and End-Point IoT Devices
- Performance Efficiency Leading AI Accelerator for Mobile and Edge Devices
- High-Performance Edge AI Accelerator
- Ultra-low-power AI/ML processor and accelerator