








You are here:
AI accelerator (NPU) IP - 32 to 128 TOPS
The Origin E8 is a family of NPU IP inference cores designed for the most performance-intensive applications, including automotive and data centers. With its ability to run multiple networks concurrently with zero penalty context switching, the E8 excels when high performance, low latency, and efficient processor utilization are required. Unlike other IPs that rely on tiling to scale performance—introducing associated power, memory sharing, and area penalties—the E8 offers single-core performance of up to 128 TOPS, delivering the computational capability required by the most advanced LLM and ADAS implementations.
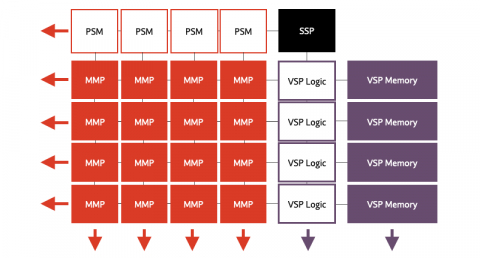
Expedera's scalable tile-based design includes a single controller (SSP), and multiple matrix-math units (MMP), accumulators (PSM), vector engines (VSP) and memory to store the network. Specific configurations depend on unique application requirements. The unified compute pipeline architecture enables highly efficient hardware scheduling and advanced memory management to achieve unsurpassed end-to-end low-latency performance. The patented architecture is mathematically proven to utilize the least amount of memory for neural network (NN) execution. This minimizes die area, reduces DRAM access, improves bandwidth, saves power, and maximizes performance.
Expedera's scalable tile-based design includes a single controller (SSP), and multiple matrix-math units (MMP), accumulators (PSM), vector engines (VSP) and memory to store the network. Specific configurations depend on unique application requirements. The unified compute pipeline architecture enables highly efficient hardware scheduling and advanced memory management to achieve unsurpassed end-to-end low-latency performance. The patented architecture is mathematically proven to utilize the least amount of memory for neural network (NN) execution. This minimizes die area, reduces DRAM access, improves bandwidth, saves power, and maximizes performance.
View AI accelerator (NPU) IP - 32 to 128 TOPS full description to...
- see the entire AI accelerator (NPU) IP - 32 to 128 TOPS datasheet
- get in contact with AI accelerator (NPU) IP - 32 to 128 TOPS Supplier
Block Diagram of the AI accelerator (NPU) IP - 32 to 128 TOPS

AI accelerator IP
- AI accelerator (NPU) IP - 16 to 32 TOPS
- AI accelerator (NPU) IP - 1 to 20 TOPS
- Deeply Embedded AI Accelerator for Microcontrollers and End-Point IoT Devices
- Performance Efficiency Leading AI Accelerator for Mobile and Edge Devices
- High-Performance Edge AI Accelerator
- Ultra-low-power AI/ML processor and accelerator