7 µW always on Audio feature extraction with filter banks on TSMC 22nm uLL









You are here:
Compact neural network engine offering scalable performance (32, 64, or 128 MACs) at very low energy footprints
The Cadence® Tensilica® NNE 110 offers an energy-efficient hardware-based AI engine that can be paired with a Tensilica based DSP. The NNE 110 targets a variety of applications including audio, voice, and speech AI, lightweight vision AI, and always-on multi-sensory applications.
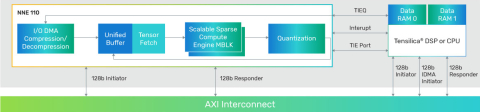
The product architecture natively supports the most common network layers found in these applications including convolution, depth-wise separable convolution, fully connected, LSTM, pooling, reshaping, and concatenation layers. Other layers can be supported (and further accelerated using TIE) using the host Tensilica DSP. The NNE 110 provides performance scalability from 32 to 128 MACs for 8x8-bit MAC computation, suiting a variety of low-power AI needs. It offers unique features for AI enhancement including hardware-based sparsity for compute and bandwidth reduction as well as on the-fly weight decompression for smaller system footprints.
The product architecture natively supports the most common network layers found in these applications including convolution, depth-wise separable convolution, fully connected, LSTM, pooling, reshaping, and concatenation layers. Other layers can be supported (and further accelerated using TIE) using the host Tensilica DSP. The NNE 110 provides performance scalability from 32 to 128 MACs for 8x8-bit MAC computation, suiting a variety of low-power AI needs. It offers unique features for AI enhancement including hardware-based sparsity for compute and bandwidth reduction as well as on the-fly weight decompression for smaller system footprints.
View Compact neural network engine offering scalable performance (32, 64, or 128 MACs) at very low energy footprints full description to...
- see the entire Compact neural network engine offering scalable performance (32, 64, or 128 MACs) at very low energy footprints datasheet
- get in contact with Compact neural network engine offering scalable performance (32, 64, or 128 MACs) at very low energy footprints Supplier
Block Diagram of the Compact neural network engine offering scalable performance (32, 64, or 128 MACs) at very low energy footprints

AI IP
- RT-630 Hardware Root of Trust Security Processor for Cloud/AI/ML SoC FIPS-140
- RT-630-FPGA Hardware Root of Trust Security Processor for Cloud/AI/ML SoC FIPS-140
- NPU IP for Embedded AI
- RISC-V-based AI IP development for enhanced training and inference
- Tessent AI IC debug and optimization
- NPU IP family for generative and classic AI with highest power efficiency, scalable and future proof