|
|
|
|
|
|
|
|
|||
|
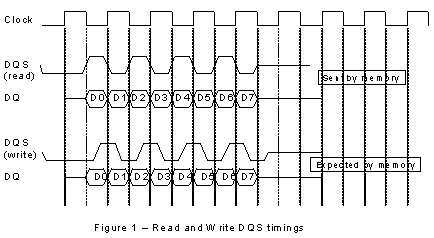
External Memory Interfaces: Delivering Bandwidth to Siliconby Alan Page Introduction Double Data Rate – what is the attraction? In the current market for electronic products customers are having ever higher expectations of product performance. The effect of this in the memory market is that designers are demanding more bandwidth from a given device, yet technologies and hence clock rates broadly stay the same. One solution to this problems is to get more data through the available pins on a memory device for a given clock rate. Double Data Rate achieves this by transferring twice as much data through each pin, by the simple expedient of sending two words of data for each clock cycle, as opposed to the traditional one. This implies that the speed of data transfer inside a DDR device is double that of a conventional SDRAM. In fact it is not the case (impossible due to the sharing of similar technologies) and the speed-up is accounted for by using two internal data busses (or one of double width). This has some impact on latency and recovery times which need to be considered when using DDR devices. Transferring data on both edges of the clock brings new technical challenges that are exacerbated by the high clock rates now available. A complete new clocking scheme is needed, together with a reduction in delay between memory and controller, and revised drivers to deal with signal integrity issues. In addition to this system considerations have to be taken into account in order to fully benefit from the new-found bandwidth available using Double Data Rate techniques. These issues are discussed below, with some ideas about how to circumvent them. Clock Schemes for DDR designs The conventional system clock (as for single data rate DRAMs) is replaced by a differential clock signal (for better noise immunity and edge detection) while for data transfers by a new signal is introduced called DQS. This signal is a bi-directional data strobe that is used for both read and write operations, however the handling of timing is slightly different in each case, with data and strobe edge aligned for read and centre aligned for write (see Figure 1). One DQS signal is associated with a number of data bits, usually 8 (but can also be 4 or 32), and the idea is that the DQS and corresponding data lines experience a similar environment (capacitive loading, routing etc.) which allows the timing skew between them to be minimised and hence a higher data rate to be achieved. As the same strobe is used for both read and write operations (and is controlled by the memory device or controller respectively) a protocol for the usage of the DQS has to be established. This protocol is described below.
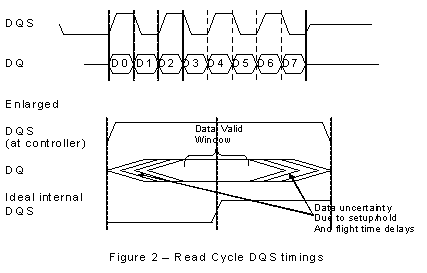
Read Cycle This edge alignment of data and DQS presents a problem when the data arrives at the memory controller. Although nominally edge aligned, there may be positive or negative skew with respect to the DQS and in any case the data ideally needs to be sampled in the middle of it's data valid window (See Figure 2). The techniques to achieve an ideal DQS/data alignment are various, ranging from using a board based propagation delay, via quarter and half cycle clock delay to sophisticated Delay Locked Loop (DLL techniques), which align data and DQS to within one hundredth of a clock cycle. The choice a designer makes is dependent on the system performance but the available timing slack can be quite small. Taking a clock period of 10ns, equivalent to a relatively slow 100MHz system clock. The available half cycle time is nominally 5ns, however setup and hold times narrow this window, typically by around 750ps each (accounting for jitter, described later), leading to a data valid window of 3.5ns. This sort of window can be accommodated via a simple quarter clock delay element. However, devices are shortly available at clock rates up to 250-300MHz. At these frequencies the data valid window is getting to the region of 1ns, and here more sophisticated techniques are required. Write Cycle
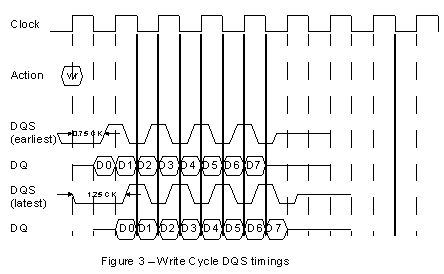 Considerations for bandwidth To a certain extent advantage can be taken of concurrency in dynamic devices. It is possible to take advantage of the banked structure of the memory devices to access data in one bank, while completing operations in a second. This brings into play the idea of bank cycling. This technique requires that reads and writes from different rows are not done sequentially within the same bank, but occur sequentially in different banks. Opening a row for access requires a sequence of actions (selecting row followed by column) which are summed into the CAS latency for the device. DDR devices typically have CAS latencies of between 1.5 and 3 clock cycles. Obviously if the designer has to wait for 2 clock cycles before getting data each time, then the overall throughput of the device will suffer. The workaround is to arrange to access data in sequential banks, which allows the overhead of enabling rows and accomplishing precharging to be done in parallel, thus minimising the overhead. Bank cycling does however impose some restrictions. The bank address lines occupy some space (two bits) in the overall memory map. In order to be able to read sequentially from each bank in turn the data must be arranged such that the addressing requires a sequence through the 4 banks in turn. For predictable systems this is possible, but for less predictable systems where data is highly random (such as graphics processing or networking) an alternative may be needed. An improvement in throughput can be achieved by careful design of the memory controller. If a queuing system is implemented then the controller can use look-ahead techniques to see which addresses need to be accessed and minimise any unnecessary row closures. Alternatively the use of specialised double data rate devices may be more appropriate. These are described below. Specialised DDR devices RLDRAM offers an 8 bank structure, with hidden precharge times, whereas FCRAM retains the 4 bank architecture, but uses hidden precharge to improve access time and partial word line activation to reduce power consumption. In general these techniques decrease latency and improve access times for random accesses, however there are some constraints that may act against the improvements. For instance FCRAM cannot interrupt a command, which means memory accesses must be word aligned, or a read-modify-write technique used if byte aligned data access is needed. These types of restrictions must be studied carefully to ensure that potential performance improvements can indeed be realised. DDR Specific Design Considerations Device Initialisation Firstly, the power supplies to the device must be established in the correct order. First the main power supply VDD (which can be 3.3 or 2.5 volts dependent on device) must be applied. Secondly the data bus power supply VDDQ (2.5 volts) must be applied, and then last of all VREF the reference voltage for the SSTL2 pads, which should be applied simultaneously as the system VTT termination voltage. VREF is defined as half the VDDQ of the transmitting device and has a quite stringent noise immunity specification, with less than 50 mV of noise being allowed on the input. During the establishing of these voltages the CKE (clock enable) pin should be held low to ensure that all DQ and DQS signals are high-impedance. Once all voltages are stable a pause of 200 usec is necessary before applying any commands. The first command that should be applied is a Precharge all, followed by setting of the internal register of the device. The internal mode register settings define the operation of the device, from CAS latency to burst length and burst mode to enabling and disabling the internal DLL.. Data Masking Refresh operation IO Drivers A typical termination network is a 25 ohm resistor between driver and load, with a parallel 50 ohm resistor connected to the threshold voltage VTT. This network can be varied according to driver class of which there are three. The above network applies to a class 1 driver, which must be able to drive 7.6mA. The paralleled 50 ohm resistor can be changed to a 25 ohm value for a class 2 driver (15.2mA). Some device manufacturers support a lower level drive capability which is designed for matched impedance networks, that employs a 5mA drive capability. It is an option to use LVTTL pads for the command lines, similar to all pins on a SDRAM device. Summary
|
|||
|
|
|
|
|
Home | Feedback | Register | Site Map |
|
|
|
All material on this site Copyright © 2017 Design And Reuse S.A. All rights reserved. |