
Lafayette, USA
Abstract:
As technology scales toward deeper submicron, the integration of a large number of IP blocks on the same silicon die is becoming realistic, thus enabling large-scaling parallel computations such as those required for multimedia workloads. Traditional shared-bus based on-chip communication architectures generally have limited scalability due to the arbitrary and non-pipelining nature of the buses. Network-on-chip (NOC) architectures have been recently proposed as a promising solution to the increasing complex on-chip communication problems. This paper presents a new NOC switch architecture which we have called CTCNOC (Central caching NOC) to offer an attractive way to reduce the system area overhead and increase system performance. The head-of-line and deadlock problems have been significantly alleviated. Through experimentation it has been shown that the proposed architecture not only exhibits hardware simplicity, but also increases overall system performance.
1. Introduction
System-on-chip (SOC) communication architecture is the fabric that integrates heterogeneous components and provides a mechanism for them to exchange data and control information. According to ITRS, ICs will have billions of transistors, with feature sizes around 50nm and clock frequencies around 10GHz in 2012. [1] The increasing number of system components is leading to rapidly growing on-chip communication bandwidth requirements. As a result, the role played by on-chip communication architecture is becoming a critical determinant of system-level metrics such as system performance and power consumption which depends more on the efficient communication among master cores and on the balanced distribution of the computation among them, rather than on pure CPU speed. [2,3]
The most widely adopted interconnected architecture for SOC designs is still bus-based which consists of shared communication resources managed by a dedicated arbiter that is responsible for serializing access requests. The advantages of the shared bus architecture are simple topology, low area cost, and extensibility. However, such approach has several shortcomings which will limit its use in future SOCs, such as non-scalability, non-predictable wire delay and power consumption. NOC architectures have been recently proposed as a promising solution to the increasing complex on-chip communication problems, due to the following reasons: energy efficiency and reliability, scalability of bandwidth, reusability and distributed routing decisions.
A NoC can be described by its topology and by the strategies used for routing, flow control, switching, arbitration and buffering. Switching is the mechanism that gets data from an input channel of a router and places it on an output channel, while arbitration is responsible to arrange the use of channels and buffers for the messages. The switch architecture and algorithm designs are generally facing with two major problems: head-of-line and deadlock. Deadlock occurs when a cyclic dependency among switches requiring access to a set of resources so that no forward progress can be made, no matter what sequence of events happen. Head-of-line will happen when the head of a buffer is stalled by the requesting resource, while all other messages in that buffer have to be blocked no matter if their targeting resources are available. [4,12]

Figure 1. The proposed router architecture
In this paper, we present a new switch architecture and switching algorithm design as shown in Fig.1. The embedded central caches, anlong with our proposed switch architecture and switching algorithm have efficiently alleviated the head-of-line and deadlock problemsÂCthus improving system performance with relative low extra system cost. It has been shown that system perforamcne in term of average communication latency and network throughput have been significantly improved.
This paper is organized as follows. Section 2 discusses works related to this study. Section 3 details our new architecture design. The test systems and results are presented in Section 4. Finally, Section 5 concludes the paper.
2. Related Works
Presently, a number of papers [4-11] have been published discussing issues related to the problems described above. Two better proposals among them are BlackBus system [7] and Virtual Channel Architecture [8]. BlackBus system employs network routers internally. Sender and receiver nodes can treat as if it were a dedicated bus. This interconnection structure results in smaller hardware on the routers and simpler network interface in each node as shown in Fig. 2. However, it needs extra wires and control scheme for the local ID creation and transformation.
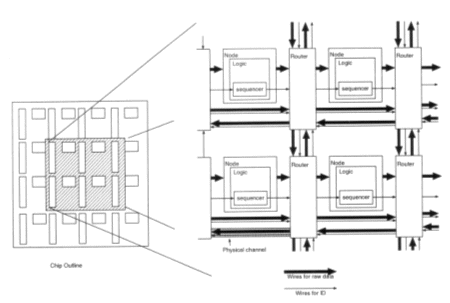
Figure 2. Architecture of BlackBus
Virtual channel architecture employs an array of buffers at each input port. By allocating different packets to each of these buffers, packets from multiple packets may be sent in an interleaved manner over a single physical channel as shown in Fig.3. This improves both throughput and latency by allowing blocked packets to be bypassed. But it leads to higher system cost and a relatively complicated arbitration process.

Figure 3 Architecture of Virtual channel Routers
3. Proposed CTCNOC architecture
Our proposed architecture is solving the problems with a relative low system cost and high throughput. The key idea of our CTCNOC architecture and switching algorithm is to reduce the affect of head-of-line and deadlock by embedding a small central cache into every switch. The stalled head packet of any buffer can be intermediately stored in the caches if the requesting resources of the following packets in the buffer are available so as to let the blocked packets to be bypassed without delay, thus increasing the throughput and average communication latency of the system.
3.1 The architecture of the proposed design
The proposed architecture is shown in Fig.4.

Figure 4. The proposed Central Caching NOC
For simplicity, we employed a mesh network (with bidrectional links) together with dimension ordered (XY) routing.
The switch architecture consists of five input buffers for the local IP core and 4 different directions respectively, an arbitration unit which collects the control information and makes the arbitrations, a crossbar and a dedicated intermediate central cache to temporally store the head packets from the buffers as shown in Fig. 5.

Figure 5. The Caching scheme
The arbitrator keeps a set of small lookup tables which store the local output channel addresses of the first three packets for the buffers. The local addresses are obtained by decoding the destination XY address of each head packet when it was stored into the respective buffers.
3.2 The proposed switching algorithm
First, the arbitrator collects the availability information of the output resources from the neighboring switches. If any of the resources is available, the arbitrator will check the cache and lookup tables for the input buffers (in the order of cache, East, North, West and South buffers; obviously cache has the top priority in the sequence) and pickup a winner for the output port. The switching algorithm is described in pseudo-code form as follows:
Cache[0..7];
bufferE[0..7];
bufferN[0..7];
bufferW[0..7];
bufferS[0..7];
addr[1..4];
do {
for (i=1;i<=4;i++)
if (outputport_av[i]==1)
begin
for (j=0;j<=7;j++) // check cache
if (cache[j]==addr[i])
forward cache[j] packet to the output port;
break;
if (bufferE[0]==addr[i]) // check bufferE
begin forward the packet to output port i;
shift the bufferE;
break;
end
else if (bufferE[1] or bufferE[2]==addr[i])
begin forward the packet to output port I;
shift the bufferE;
break;
end
else if ( bufferN[0]==addr[i]) // check bufferN
......
else if ( bufferW[0]==addr[i]) // check bufferW
......
else if ( buffers[0]==addr[i]) // check bufferS
......
end
}
4. Simulation results
4.1 Design Complexity and speed
We implemented the cache architecture and mapped it to Xilinx Vertex2Pro FPGA. The targeting device was xc2vp2, package fg456 with speed -6. Xilinx ISE 8.1i was used to perform the synthesizing and timing analysis. The results showed that the equivalent gate count for the central cache architecture is only 1230 meaning a relative small extra system cost to the system. Its delay is only 3.018ns, so that it can work in the system with maximum speed 331.35MHz.4.2 Latencies VS Throughput
Network latency is obtained by calculating the time (clock cycles) the first packet is created to the last packet is received at its destination. Each node injects 50 packets into the network. The network is a 6X6 mesh, each router has 5 input and 5 output ports. Network throughout is measured by calculating how many packets can be transferred within one clock cycles.
The simulation has been carried out twice with and without integrating the proposed central caches.

Figure 6. Simul ation setting up
The table below shows the effect on the average latency for varied cache sizes. Where a cache size of 0 is a cacheless design. Our experimental results show a 16% reduction if average latency when a cache size of 1 if used and a 22% reduction for a cache size of 2 and 3 as shown in Fig.7.
Table 1. Latency and throughput with varied cache sizes
| Cache Size | 0 | 1 | 2 | 3 |
| Average Latency (clk cycles) | 37 | 31 | 29 | 29 |
| Throughput | 2.1 | 2.6 | 2.9 | 2.9 |
The results also show a 24% increase in the throughput of the system when a cache size of 1 is used and a 38% increase with a cache size of 2 and 3 as shown in Fig.8.

Figure 7. Average Latency versus Cache size

Figure 8. Throughput versus Cache size
As you may note from Fig.7. and Fig.8., the trend of the average latency and throughput stop changing after we increased the cache size over 3 as we expected. The reason could be: (1) caches have the highest priortiy over other input buffers on the arbitraterÂfs checking list. When any of the output ports is available, the packets stored in the caches will be swithced first if it happens to be the resource the packets are requesting ; (2) in current level of traffic density (50 packets/ per node), it seems only no more than 3 cache slots are needed to deal with the head-of-line and deadlock problems ; however as the traffic density increased, more cache slots will automatically be involved in the switching process.
5. Conclusion
A new central caching NOC communication architecture is presented in this paper. Test results demonstrate that the new architecture and the algorithm are capable of improving the system performance (latency VS throughput) by reducing the effect of head-of-line and deadlock problems. At the same time, it only brings a relative small extra cost to the system. In the future, we hope to show that many real applications can benefit from the proposed architecture
References
[1] International Technology Roadmap for Semiconductors
[2] K.Lahiri, S.Dey and A.Raghunathan, ÂgOn-chip Communication: System-level Architectures and Design MethodologiesÂh, 2001.
[3] F.Poletti, D.Bertozzi, L.Benini, and A.Bogliolo, ÂgPerformance Analysis of Arbitration Policies for SOC Communication ArchitectureÂh, in Proc. Design Automation for Embedded System, 2003, pp. 189-210.
[4] C.A.Zeferino and A.A.Susin, ÂgSoCIN: A Parametric Scalable Network-on-chipÂh, in Proc. IEEE SBCCI, 2003
[5] B.Vermeulen, J.Dielissen, K.Goossens, and C.Ciordas, ÂgBring communication networks on chip: test and verification implicationsÂh, IEEE Communication Magazine, Vol. 41, No.9, Sep 2003, pp. 74-81.
[6] A.S. Lee, and N.W. Bergmann, ÂgOn-chip Communication Architectures for Reconfigurable System-on-chipÂh, in Proc. IEEE FPT Conf., 2003.
[7] K.Anjo, Y.Yamada, M.Koibuchi, A.Jouraku and H.Amano, ÂgBLACK-BUS: A New Data-transfer Technique using Local Address on Networks-on-chipÂh, in Proc. IEEE 18th IPDPSÂf04, 2004
[8] N.Kavaldjiev, G..Smit and P.G.Jansen, ÂgA Virtual Channel Router for on-chip NetworksÂh, in Proc. IEEE Intl. SOC Conf., Sep 2004, pp 289-293.
[9] S.Lee, C.Lee and H.Lee, ÂgA New Multi-channel On-chip-bus Architecture for System-on-chipsÂh, IEEE International SOC Conference 2004, Sep 2004, pp 305-308.
[10] J. Henkel, W. Wolf, S. Chakradhar, ÂgOn-chip networks: a scalable, communication-centric embedded system design paradigmÂh, in 17th International Conference on VLSI Design, 2004, pages 845- 851.
[11] E. Beigne, F.Clermidy, P. Vivet, M. Renaudin, A. Clouard, ÂgAn Asynchronous NOC Architecture Providing Low Latency Service and its Multi-level Design FrameworkÂh, in ASYNC 05 Int. Conference, 2005
[12] A. Clouard et al., ÂgUsing Transaction-Level Models in a SoC Design FlowÂh, in SystemC: Methodologies and Applications, edited by W. Muller, W. Rosenstiel, J. Ruf, Kluwer Academic Publishers, 2003, pp. 29-63.