
Rambus Chip Technologies India (Pvt) Ltd.
Bangalore, India
Abstract:
Interconnect standards such as PCI Express, Hyper Transport and Rapid IO have several common features such as packet based transmission, flow control for buffer space management, data integrity checks and packet retransmission upon failure of delivery. Implementation of such systems is complex and come with an overhead in terms of latency. Buffer size limitations and flow control protocol requirements determine the data rate that can be achieved in practical systems. Although these interconnects promise high performance with associated scalability, it is important to exploit the configurable options that they offer in order to harness the maximum performance. As more systems integrate these interconnects as IP components, verifying them for performance at component level is becoming a key aspect in the design cycle. This paper describes challenges involved in realizing the maximum performance of a configurable interconnect IP (GPEX - Rambus PCI Express Digital Controller). The following sections describe how various performance metrics such as roundtrip latency and bandwidth can be used to characterize a PCI Express IP performance and its impact on the system. The ideas presented can also be applied to other high speed interconnect architectures like RapidIO and Hypertransport
INTRODUCTION
Broadly, two classes of parameters that affect the performance are related to PCI Express protocol specification and design implementation. It is critical to exploit the configurable options that are offered by the PCI Express specification in order to improve performance of the IP in its selected configuration. Some options include packet size and flow control credit availability. It is also equally critical to carefully select the design specific parameters that impact performance. These parameters include choice of the interface with the application layer, clocking scheme, retry and receiver buffer sizes and flow control credit release latencies. It must be noted that a mismatch in selecting these parameters or improper architecture may adversely affect the performance.
PCI-EXPRESS – An Overview
PCI Express [1] is a successor of PCI bus designed to address the high IO bandwidth requirements in compute and communication platforms. It is a high performance serial point to point interconnect that is scalable and supports PCI compatible software model. It supports advanced features for power management, quality of service, data integrity checks and error handling. An example of a system based on PCI Express is shown in Figure 1.

Figure 1: Typical PCI Express Topology
A typical PCI Express controller consists of MAC, Data Link Layer (DLL) and Transaction Layer (TL) in addition to other blocks including configuration registers. The TL is connected to an application or user logic. The MAC layer is connected to the PCI Express PHY over the PIPE interface. The PHY is connected to the PCI Express link as shown in Figure 2.

Figure 2: PCI Express Layered Architecture
PCI-EXPRESS IP PERFORMANCE METRICS
The performance of a PCI Express link depends on the characteristics of both the transmitting device and its link partner -the receiving device. Two metrics can be used to measure the performance of the link: (a) Effective band-width or data rate measured on the link (b) The latency of the PCI Express controllers.
Bandwidth is the rate at which data can be transmitted or received on the PCI Express link. The peak bandwidth of PCI Express link is 250 MB/sec per lane. The bandwidth of a link can be calculated using the following formula:
Bandwidth = (# useful bytes) * (Peak bandwidth) / (total # bytes transmitted)
Bandwidth can be measured at several levels depending on what information is considered as useful. Other than the data transmitted, every Transaction Layer Packet (TLP) that is transmitted has some overheads such as associated header information (12 or 16 bytes), data integrity and error recovery information and packet framing symbols (8 or 12 bytes). To calculate the bandwidth of actual payload transmitted, only the data portion of TLP is considered as useful. All the other components of TLP or the TLP overhead and the idle bytes are factored into the total bytes transmitted. Similarly, if all information other than idle symbols are considered as useful bytes, then the TLP overheads are also included as part of # useful bytes.
Latency is the number of clocks taken by a PCI Express controller to process a packet. Different latencies that contribute to the overall latency include the following:
Receive data path latency, Transmit data path latency, Ack release latency, Ack processing latency, Credit release latency and Credit update latency
FACTORS AFFECTING PCI-EXPRESS PERFORMANCE
Key factors governing the performance of a PCI Express link are listed below.
- PCI Express Link Width
- Maximum Payload Size
- Core clock frequency
- Transmit device’s retry buffer size
- Receive device’s receiver buffer size
- Transmit and Receive device’s data path latency
This section describes each of these factors and their effect on the overall performance.
PCI Express Link Width and Maximum Payload Size (MPS)
Link width
A PCI Express IP can support any link width - 1, 2, 4, 8, 16 or 32. The higher the link width, the faster any packet can be transmitted on the link. The number of active lanes in a link is dependent on the maximum link width that can be supported by both the devices connected to the link. On wide link width a TLP of given length will be transmitted faster when compared to a narrow link as more bytes can be transferred in a single bit time. Therefore this will affect latency of transmitting/receiving a TLP over the link.
Maximum Payload Size (MPS)
A PCI Express device can support a maximum payload size per TLP from 128 bytes to 4 KB. When MPS is large, the number of TLPs required to transmit the same amount of data is less. Therefore, higher effective bandwidth can be achieved due to reduced TLP overheads.
The time taken to transmit or receive a TLP of a given length at can be represented as
tTLP = [( SHEADER+SPAYLOAD+SOVERHEAD) / LW] * tPIPE
Where
tTLP - Time taken for the TLP to be transmitted on the link, tPIPE - Clock period of PIPE clock. This fixed based on the width of the PIPE interface as follows – 4ns for 8-bit PIPE; 8 ns for 16-bit PIPE
SHEADER – Size of the header of the TLP in bytes,
SPAYLOAD – Size of the Payload associated with the TLP in bytes,
SOVERHEAD – DLL and MAC framing overheads associated with the TLP in bytes. This is a fixed value of 8 bytes (LCRC and Sequence number), LW – Link width
The sizing of the Rx buffer is usually based on the worst case scenario where only MPS sized packets are received from the far end device. Therefore the value of tTLP must be calculated based on the MPS size of GPEX supported. For further analysis it is assumed that the Rx buffer size is optimized for MPS sized packets. With this assumption the time taken to transmit a TLP of size MPS supported by GPEX can be calculated based on tTLP with payload size set to MPS as
tMPS = [ ( SHEADER+MPS+SOVERHEAD) / LW ]* tPIPE
The quantity tMPS is a fixed value and is dependent on the MPS supported by GPEX and the link width. This quantity is used to normalize the latency in terms of a link width and MPS supported. The value of tMPS has bearing on the receive buffer and retry buffer size. The sizing of these buffers must be done according to the value of tMPS. A large value of tMPS helps in absorbing higher credit release and Ack latency (described in the next section) which will in turn help in reducing receive and retry buffer size. In addition a large tMPS helps in increased efficiency on the link as more data is transferred.
Device Latency
The data path latency of a device as well as the latency to transmit and process ACK and Update FCs play a significant role on the link performance. For ease of analysis the latency involved in processing a packet can be divided into 2 categories
- Packet transmission latency
- Packet reception latency
Packet Transmission Latency
The sequence of operation is illustrated on the timeline shown in Figure 3. The sequence starts with a TLP initiated by the User Logic (UL) through the UL-TL interface. Once the TLP has been accepted by GPEX (at time t1) GPEX performs several operations like TLP formation, steering, storing in retry buffer and clock synchronization (if required) and presents the TLP on the PIPE interface (at time t2). The latency involved for this operation is referred to as transmit data path latency. At t2, the TLP is already stored in the retry buffer and subsequently waits for the Ack from the far end device. The far end device depending on its own characteristics will take some time before generating the Ack for the TLP (at time t3). The latency in generating the Ack for the far end device is referred to as far end device Ack latency. Once GPEX receives the Ack for a TLP it releases the retry buffer resource for that TLP i.e. the TLP is flushed out from the retry buffer (time t4). This latency is referred to as GPEX Ack processing latency. At this point the lifetime of a TLP ends. Subsequently, the credit is released through an UpdateFC credit packet for the TLPs by the far end device. The latency involved in every step of the sequence is labeled in the figure. The time elapsed from when a packet is initiated from the UL to the time when the Ack is received for the TLP and retry buffer space is released is referred to as roundtrip ack latency. This can be defined in terms of the individual latencies as
Roundtrip Ack latency = Datapath Latency + Far end device Ack latency + GPEX Ack processing latency

Figure 3 : Packet transmission latency
Packet Reception Latency
The sequence of operations is illustrated on the timeline in figure 4. The sequence starts with a TLP being received at the PIPE interface of GPEX receiver. GPEX performs a series of operations on the received TLPs like descrambling, lane-to-lane deskew (for link width > x1), LCRC checks, Store and Forward operation (if enabled), TLP decoding. , TLP scheduling and VC arbitration and deliver the TLP to the UL interface. Time to complete these operations is referred to as receive datapath latency. Before the TLP is delivered to the UL, GPEX DLL performs LCRC checks on the TLP and if it determines that the packet integrity is good it generates the Ack for the TLP. Timely generation of Ack DLLP by GPEX is important to prevent starvation of retry buffers at the far end device. The latency involved in generating the Ack by GPEX is referred to as Ack latency. Since buffer management is done within a PCI-Express IP the latency in reading out a packet from the buffer and releasing the resources related to the packet after it has been read is a crucial factor. An efficient credit release mechanism prevents credit starvation. The latency involved in releasing a flow control credit and transmitting an UpdateFC to the far end device is referred as UpdateFC latency. Once the UpdateFC DLLP is generated by GPEX and received at the far end device, the far end device has a fixed latency to update the credit counters. This is referred to as the Far end device UpdateFC processing latency. The latency from the time the TLP is received at the PIPE of GPEX till the UpdateFC DLLP generated by GPEX is received at the far end device and is processed is referred to as roundtrip credit release latency.
 Figure 4 : Packet reception latency
Figure 4 : Packet reception latency
Roundtrip latency in both transmit and receive directions affect the bandwidth that is available and can lead to performance degradation. The effect of these is studied in later sections
Core Clock Frequency
The higher the core clock frequency of a PCI Express controller, the faster it can process data. This will help in improving the data path latency component of the roundtrip latency in both transmit and receive directions.
Retry Buffer Size
PCI Express implements data integrity checks on every TLP or DLLP using a link level CRC and retry mechanism. Whenever a packet is received by a device, it gives a positive or negative acknowledgment to its link partner to indicate that it received the packet without any data integrity or CRC failures. Whenever a transmitting device receives a NAK from the link partner it means that there was a data integrity failure and the packet has to be re-transmitted. In order to implement retry, every device must store all the packets that were transmitted until an ACK was received for the packet. If this buffer is full, then a device cannot transmit any more packets on the link until an ACK is received from the far-end device. This could lead to idle state on the link. Therefore, the size of the retry buffer plays a very important role in the performance on the link.
A small retry buffer means that the transmitter is forced to insert idle states on the link frequently resulting in poor link bandwidth. Additionally, the latency in processing the packet and sending the acknowledgement to the far end device also affects the rate at which a transmitter can send packets. Hence, optimal sizing of the retry buffer based on the latency to generate acknowledge is crucial for sustaining the desired performance.
Consider the example shown in figure 5. This example assumes that PCI-E Device1 is transmitting packets of size MPS. PCI-E Device1 is configured to have a retry buffer that can hold 3 MPS sized packets. This scenario in Figure 5(i) shows the case when no transmission stalls occur. In this case the latency in generating the Ack by PCI-Device2 is less than 3*tMPS and hence the Ack DLLP from the PCI-E Device2 arrived between the second and third packet transmission. If the transmitter of PCI-E Device1 can schedule the next packet before it completes transmitting the third packet (i.e. the internal latency in processing the Ack DLLP is small) a transmission stall can be prevented and PCI-E Device1 can send back to back packets at a sustained rate. If the transmitter of PCI-E Device1 cannot schedule the next packet before it completes the third packet transmission stall will occur even if the far end Ack generation latency is less than 3*tMPS. Transmission stall can be prevented in this case if the internal processing latency of PCI-E Device1 is bound as follows
Internal process latency < 3*tMPS - tACK,
Where tACK - is the time at which the Ack ends
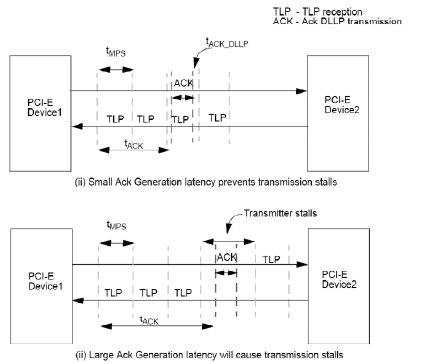
Figure 5 : Illustration of Ack generation latency
Figure 5(ii) depicts the case when transmission stalls occur due to large Ack Generation latency. In this case the Ack generation latency of the PCI-E Device2 is greater than 3*tMPS. Since the retry buffer of PCI-E Device1 is large enough to hold 3 MPS sized packets the transmission is stalled after transmitting 3 MPS sized packets since the Ack for the first packet is pending.
From the illustrations in figure 5, it is evident that the transmitter rate is throttled due to lack of retry buffer space if it is not sized optimally. This situation can be avoided if the Ack latency is small enough so that the retry buffer is not filled completely i.e. retry buffer should be large enough to absorb the Ack latency. In general the Ack latency can be visualized as loop starting from the transmission of the TLP by a PCI-E Device. Various components of this loop are illustrated in Figure 6. Each component of the loop can be broken down into portions related to the GPEX or a characteristic of the far end device.

Figure 6 : Roundtrip Ack latency
-
Path I - The packet takes a fixed latency through the datapath of the GPEX.
-
Path II - The packet takes a fixed time to be transmitted on the link based on the link width and size of the packet.
-
Path III - The packet is processed by the far end device and the Ack is released.
-
Path IV - Once the Ack is received the retry buffers resource is released and the next packet is loaded into the retry buffer from the TL.
Optimal Retry Buffer Sizing

Figure 7 : Transmit performance Vs roundtrip Ack latency
The family of curves in figure 7 depicts the trend of transmit link utilization with respect to the roundtrip latency for a given size of the retry buffer. This family of curves can be used to determine the optimal retry buffer size required for sustaining a given transmit utilization. For example if the characteristic of the peer device interaction with the GPEX is known i.e. its Ack generation latency, then by setting that value to the PCI-E BFM and by gathering the data generated by the performance monitor, the overall roundtrip latency in generating the Ack can be computed. This latency can be superimposed on to the family of curves in Figure 7. The curve with which the vertical line indicating the roundtrip latency intersects will directly give the optimal retry buffer size for the application.
Receive buffer Size
A PCI Express receiver stores all the received packets in a buffer until it is ready to be processed by the application logic. A transmitting device is allowed to transmit a packet only when there is sufficient space available in the receiver buffers to store the incoming packet. This is implemented using the credit based flow-control mechanism. When a transmitter determines that it does not have enough credits to transmit a packet on the link no further packet can be transmitted until credit is released by the link partner using flow control update DLLPs leading to link starvation. Hence, link performance is very sensitive to receive buffer size
The credit based flow control mechanism is implemented in the Transaction Layer (TL) in conjunction with the Data Link Layer. Flow control mechanism allows each transmitter to track the amount of buffer space that is available in the far end receiver and prevents the transmitter from sending packets when there is not enough buffer space at the far end receiver. This will prevent receiver buffer overflows. Another situation that can result in credit starvation could be latency in updating credits. Whenever a receiver receives a packet, it is required to send credit updates to the far end device after the packet is processed. If the delay in generating the updates is significant then it could lead to credit starvation situation. Consider the situation shown in Figure 8. This is a generalized case where 2 PCI-Express devices are interacting. Device1 transmits packets and Device2 generates the credit release packets once it processes a packet. Let the receiver buffer size of Device2 be good enough to hold 3 packets of maximum payload size. The situation in Figure 8(i) is a case when credit starvation is prevented. In this case the latency in generating the credit release is less than the time taken to transmit 3 packets. Figure 8(ii) shows a case when credit starvation occurs. In this example, credit for a packet arrives after the transmitter has transmitted 3 packets. Since the transmitter tracks the receiver buffer space available, it would stop transmission and idle after 3 packets since the receiver has not given any credits back.

Figure 8 : Credit update latency - Illustration
In general the credit release mechanism can be considered as a sequence starting from the transmission of a packet by the transmitter, processing of the same by the receiver, credit release by the receiver, and processing of the credit release by the transmitter and scheduling the next packet. This entire sequence of operation forms a loop through the transmitter and receiver and is referred to as flow control loop. The flow control loop and its components are shown in Figure 9.

Figure 9: Flow control loop
The flow control loop can be broken into 5 paths viz.
-
Path I - The packet takes a fixed time based on its length, link width to be transmitted on the link.
-
Path II - Once the packet reaches the PCI-E device, it enters the internal pipeline and is processed by its MAC and DLL layers
-
Path III - TL stores the packet in the receive buffer and the TL scheduler decides when the packet can be delivered to the application logic. When a packet is read out a credit release packet is scheduled.
-
Path IV - Credit release packet passes through the pipeline of the PCI-E device and is ultimately transmitted on the link to the PCIExpress device.
-
Path V - Once the PCI-Express device receives this credit release packet, it has its internal latency before which it can schedule the transmission of the next packet.
The sizing of the receive buffer should be optimized so that the flow control loop is compensated. This will prevent credit starvation which in turn will ensure that a given throughput level is maintained at the PCI-Express link
Optimal Receive Buffer Sizing

Figure 10 : Receive performance Vs roundtrip flow control latency
The family of curves in Figure 10 depicts the trend in receive performance with respect to roundtrip latency for various receive buffer sizes. It is evident from the graph that for a given size of the receive buffer the receive performance degrades with increasing roundtrip latency. X-axis represents the roundtrip latency normalized to the link width and MPS size supported of the device. This value is computed by dividing the actual roundtrip latency by the time taken to transmit a packet with MPS size payload. Since the time taken to transmit the packet on the link is different for different link widths normalizing this way helps in simplifying the analysis. This family of curves can be used to determine the receive buffer sizing.
SUMMARY
In this paper, we described the challenges and nuances in realizing the true potential of PCI Express in terms of performance. The numerous options provided by both the PCI Express protocol specification and the design makes the analysis challenging. We discussed the performance challenges involved in a typical PCI Express design IP. Results show the significance of optimal packet size, buffer sizes and scheduler latencies in achieving maximum performance. It is shown that values of these parameters are dictated by the application in conjunction with the peer device characteristics. The methodology described in this paper can be extended to any bus based IP design environment like Hypertransport or Rapid IO
REFERENCE
1. PCI Express Base Specification Rev. 1.1, PCISIG, March, 2005