
By Rabindra Ku. Jena, Institute of Management Tecnology, Nagpur, India
Gopal K. Sharma, ABV-Indian Institute of Information Technology & Management, Gwalior, India
Abstract:
Network on Chip (NoC) is a new paradigm for the design of core based System on Chip. It is expected to provide huge computation power due to its higher clock frequencies and parallel execution of processes. This paper addresses the problem with special reference to the topological mapping of intellectual Properties (IPs) in the tiles of a meshbased NoC. The aim is to obtain the pareto mappings that minimize: (i) the energy consumption and (ii) maximum link bandwidth, under performance constraints. As the stated problem is NP-hard, we propose a heuristic technique based on a multi-objective genetic algorithm to obtain an approximation of the pereto-optimal front. We have considered “many-many†mappings between switch and core(Tile) in our model instead of “one-one†mappings in order to reduce the congestion and energy consumption. The evaluation performed on set of random benchmarks and a real application (M-JPEG encoder) to measure the efficiency, accuracy and scalability of the proposed approach. Experimental result shows that our proposed model saved up to 70% of energy and minimized up to 20% of maximum link bandwidth in comparison to “oneone†mappings.
1. Introduction
Network on Chip (NoC) has been proposed as a solution for the communication challenges like propagation delays, scalability, infeasibility of synchronous communication etc. in a nano scale regime [4-5]. To meet these challenges under the strong time-to-market pressure, it is essential to increase the reusability of components and system architectures in a plug and play fashion [6]. Simultaneously, the volume of data and control traffic among the cores grows. So, it is essential to address the communication-architecture synthesis problem through mapping of cores onto the communication architecture [7]. Therefore this paper focuses on communication architecture synthesis to minimize the energy consumption and communication delay by minimizing maximum link bandwidth. Communication architecture synthesis is shown in the figure-1

Figure-1: Mappings for NoC synthesis problems
The input to the communication synthesis is a core communication graph (CCG) characterized by library of interconnection network elements and performance constraints. The core communication graph consists of processing and memory elements are shown by P/M in the figure-1. The directed edges between two blocks represent the communication trace. The communication trace characterized by bandwidth (bsd) and volume (vsd ) of data flowing between different cores. The output of the communication synthesis problem is the energy and throughput synthesizes NoC back bone architecture as shown in figure-1.
In this paper we address the problem of mapping the core onto NoC architecture to minimize energy consumption and maximum link bandwidth. Both of the above stated objectives are inversely proportional to each other. The above stated problem is also an NP-hard problem [11]. So, genetic algorithm is a suitable candidate for solving the multi-objective problem [8]. The optimal solution obtained by our approach saves up to 70% of energy on average in compare to other existing approaches. Experimental result shows that our proposed model is superior in terms of quality of result and execution time in compare to other approaches.
The paper is organized as follows. We review the related work in Section 2. Section 3 and Section 4 describes the problem definition and the energy model assumed in this paper. Section 5 represents the multi-objective genetic algorithm formulation for the problem. Section 6 discusses the problem formulation. Experimental results are discussed in Section 7. Finally, a conclusion is given in Section 8.
2. Related Work
The problem of synthesis in mesh-based NoC architectures has been addressed in various papers. Hu and Marculescu [5] present a branch and bound algorithm for mapping IPs/cores in a meshbased NoC architecture that minimizes the total amount of power consumed in communications. De Micheli [14] addresses the problem under the bandwidth constraint with the aim of minimizing communication delay by exploiting the possibility of splitting traffic among various paths. Lei and Kumar [15] present an approach that uses genetic algorithms to map an application on a mesh-based NoC architecture. The algorithm finds a mapping of the vertices of the task graph on the available cores so as to minimize the execution time. However these papers do not solve certain important issues. The first relates to the evaluation model used. In most of the approaches the exploration model decides the mapping to explore the design space without taking important dynamic effects of the system into consideration. Again in the above mentioned works, in fact, the application to be mapped is described using task graphs, as in [15], or simple variations such as the core graph in [14] or the application characterization graph (APCG) in [5]. These formalisms do not, however, capture important dynamics of communication traffic. The second problem relates to the optimization method used. It refers in all cases to a single performance index (power in [5], performance in [14-15].So the optimization of one performance index may lead to unacceptable values for another performance index (e.g. high performance levels but unacceptable power consumption). We therefore think that the problem of mapping can be more usefully solved in a multi-objective environment. Where there is no single solution but a set of mapping alternatives (which we will indicate as pareto mapping). The contribution we intend to make in this paper is to propose a multi-objective approach to solving the synthesis problem on a mesh-based NoC architecture. The approach will use evolutionary computing techniques based on genetic algorithm to explore the mapping space with the goal to optimize maximum link bandwidth and energy consumption.
3. Problem Definition
3.1. A Core Communication Graph (CCG) is a digraph, G(V,E), where each vertex v Є V represent core and e Є E is a communication edge having two attributes, denoted by bsd and vsd are the required bandwidth and total volume of communication respectively.
3.3 Communication Structure
The 2-D mesh communication architecture has been considered for its several desire properties like regularity, concurrent data transmission and controlled electrical parameters[3][6].In figure-1 shows a 2-D mesh NoC architecture which has ‘9’ tiles,‘9’ switches and unidirectional links. Each tiles is a square surrounded by four switches and links. Each switch is connected to its neighboring switches via two unidirectional links and each switch has multiple internal links connected to core place in adjacent tiles. To prevent the packet loss due to the multiple packets approaching to the same output port, each switch has small buffers (registers) to temporarily store the packets. Each core has network interfaces (NIs) to connect to the network via switches. NIs is responsible for packetizing and depacketizing the communication data. Each core has maximum ‘4’ NIs to communicate ‘4’ adjacent cores in parallel as shown in the figure-2. We implement static XY wormhole routing in this paper because I) it is easy to implement in switch. ii) It doesn’t required packet ordering buffer at the destination. iii) It is free of deadlock and lovelock [7] [8]. The draw of this design is that it required an additional area and control logic for additional NIs. The drawback can be tackled by the wrapper based NIs design.

Figure-2: Communication Architecture
4. Energy Model
Energy minimization is the one of the major challenging task in NoC design. In [16], Ye et al. first define the bit energy metric of a router as the energy consumed when a single bit of data goes through the router. In [5], Hu et al. modify the bit energy model so that it is suitable for 2D mesh NoC architecture. They derives mathematical expression for bit energy consume, when data transfer from switch ‘i’ to switch ‘j’ is given by
Ei,j bit = (hij + 1) ESbit + hij ELbit (1)
Where ESbit and ELbit are the energy consumed in the switches and links respectively. The variable hij represent the number of links on the shortest path. As per the expression, the energy consumption is depend on the hop distance (hij) between switch ‘i’ and ‘j’ because ESbit and ELbit constant. Note ESbit is the energy consumption due to switches is depending on the number of ports in the switches. The following sections discuss the basic ideas of problem formulation using multi-objective optimization paradigm.
5 A Multi-Objective Genetic Algorithm
In order to deal with the multi-objective nature of NoC problem we have developed genetic algorithms at different phases in our model. The algorithm starts with a set of randomly generated solutions (population). The population’s size remains constant throughout the GA. On each iteration, solutions are selected, according to their fitness quality (ranking) to form new solutions (offspring). Offspring are generated through a reproduction process (Crossover, Mutation). In a multi-objective optimization, we are looking for all the solutions of best compromise, best solutions encountered over generations are fled into a secondary population called the “Pareto Archiveâ€. In the selection process, solutions can be selected from this “Pareto Archiveâ€(elitism). A part of the offspring solutions replace their parents according to the replacement strategy. In our study, we used elitist non-dominated sorting genetic algorithm NSGA-II by Deb et al. [8].
6. Problem Formulation
6.1 Basic Idea
Like other algorithms in area of design automation, the algorithm of NoC communication architecture is a hard problem. Our attempt is to develop an algorithm that can give near optimal solution within reasonable time. Genetic algorithms have shown the potential to achieve the dual goal quite well [9,15].
As shown in figure-3 and as discussed in Sction-1, the problem is solved in two phases. The first phase is basically a core tile mapping problem (CT-GA). The input to the problem is the CCG and NoC architecture.

Figure-3: Overall design flow
The output of the first phase placed the Core in the appropriate Tiles. The tasks of the second phase are Tile-Switch Mapping using genetic algorithm (TSGA). The following Section discussed each phases in detail.
6.1.1 Core-Tile Mapping (CT-GA)
The input to the CT-GA is a Core Communication Graph (CCG) and a structure NoC backbone as shown in the figure-3. In our case it is a n×m mesh. The objectives of the mapping are (i) to reduce the average communication distance between the cores (i.e to reduce number of switches in the communication path). (ii) to maximize throughput(i.e minimize the maximum link bandwidth) under the communication constraint. Core-tile mapping is a multi-objective mapping. So we use genetic algorithm based on NSGA-II. Here the chromosome is the representation of the solution to the problem, which in this case describe by the mapping. Each tile in mesh has an associated gene which identified the core mapped to the tile. In n×m mesh, for example the chromosome is formed by n×m genes. The i-th gene identified the core on the tiles in (i / n) row and (i % n) column. The crossover and mutation operators for this mapping have been defined suitably as follows:
Crossover:
The crossover between two chromosomes C1 and C2 is generated a new chromosome C3 as follows. The dominant mapping between C1 and C2 is chosen. Its hot core (the hot core is the IP required maximum communication) is remapped to a random tile in the mesh, resulting a new chromosome C3.
{
If (C1 dominate C2)
e l s e
C3 = C2;
Return (C3);
}
The function Swap(C, i, j) exchange the i-th gene with j-th gene in the chromosome C.
Mutation:
The mutation operator act on a single chromosome (C ) to obtained a muted chromosome C0 as follows. A tile Ts from chromosome C is chosen at random. Indicating the core in the tile Ts as cs and ct as the core with which cs communicates most frequently, cs is remapped on a tile adjacent to Ts so as to reduce the distance between cs and ct . thus obtaining the mutated chromosome C0. Algorithm, given below describes the mutation operator. The RandomTile(C) function gives a tile chosen at random from chromosome C. The MaxCommunication(c) function gives the core with which ‘c’ communicates most frequently. The Row(C, T) and Col(C, T) functions respectively give the row and column of the tile T in chromosome C. Finally, the North, South, East, West(C, T) functions give the tile to the north, south, east and west of the tile T in chromosome C.
{
Chromosome C0 = C;
Tile Ts = Random Tile (C0);
Core cs = C0-1(Ts);
Core ct = MaxCommunication (cs);
Tile Tt = C0 (ct );
i f ( Row(C0 , Ts ) < Row(C , Tt ) )
}
6.1.2. Tile-Switch Mapping (TS-GA)
The Core-tile mapping as discussed in 6.1.1, maps optimally the cores into the n×m mesh. Now once the cores placed in the tiles. The next phase problem is to bind the tiles to the switches. As we discussed in section 1, our mapping is a manymany mapping from tiles to switches i.e. a tile can bind to more than one switch ( maximum 4) and a switch can connected to more than one tiles ( maximum 4). The aim of the many-many mapping is to reduce
- The hop distance between source and destination.
- Reduce the congestions at NI to increase the throughput.
Again this Tile-Switch mapping is multiobjective in nature. So we develop a GA based model (TS-GA) for the design space exploration. The input to TS-GA is the best chromosomes from CT-GA and CCG. Each gene in the chromosome is representing an edge in the CCG, which includes source and destination. So the number of genes in each chromosome is the number of edges in the CCG.

Figure-4: Chromosome representation forTS-GA
Each tile in each gene position can be bind at most four switches as shown in figure 4. The single point crossover is considered for this GA model with some random probability. For mutation, a gene from the chromosome is chosen and the switches for each tiles (source, destination) will replace with switches from the set of permissible switches with some random probability.
7. Experimental Results
This section presents the results of our multi-objective genetic formulation (MGAP). The final results i.e the result obtained after completion of TS-GA are compared with PBB algorithm [5] and PMAP algorithm [14]. For TA-GA, we consider NSGA-II multi-objective evolutionary algorithm technique with crossover probability 0.98 and mutation probability 0.01). For CT-GA, we consider NSGA-II with our introduced new crossover and mutation operator. For Table 1 shows the bit-energy value of a link and a switch of different sizes assuming 0.18 μm technology.
| ELbit | ESbit | ||||
| 4×4 | 5×5 | 6×6 | 7×7 | 8×8 | |
| 5.445 pJ | 0.43 pJ | 0.52 pJ | 0.61 pJ | 0.69 pJ | 0.78 pJ |
The value of ELbit is calculated from the following parameters.
(1) length of link (2mm) (2) capacitance of wire (0.5fF/ μm) (3)voltage swing (3.3V).
In our experiment, we consider three random benchmarks (1, 2, 3) (task graph), each benchmark contain less than ‘9’ nodes. Which can map onto a 3×3 mesh NoC architecture. The required bandwidth of an edge connect two different node is uniformly distributed over the range [0, 150Mbytes].The traffic volume of an edge is uniformly distributed over the range [0, 1Gbits].
Figure-5 shows the maximum link bandwidth utilization of three benchmarks. It is clear from the figure that our approach (MGAP) saves more than 15%-20% (on average )link bandwidth as compare to PMAP and PBB. Figure-6 shows that our approach saves 60%-70% (on average) of energy consumption.
The real time application is a modified Motion-JPEG (M-JPEG) encoder which differs from traditional encoders in three ways: (i) it only supports lossy encoding while traditional encoders support both lossless and lossy encodings.(ii) it can operate on YUV and RGB video data whereas traditional encoders usually operate on the YUV format, and (iii) it can change quantization and Huffman tables dynamically while the traditional encoders have no such behavior. We omit giving further details on the M-JPEG encoder as they are not crucial for the experiments performed here. Interested readers are pointed to [1].

Figure-5: Maximum Link Bandwidth comparisons for three random benchmarks

Figure- 6: Energy comparisons for three random benchmarks
Figure-7 shows the bandwidth requirements and energy consumptions for M-JPEG encoder application. From the figure it is clear that our approach out perform other approaches. Figure-8 shows the behavior of the NSGA-II for the M-JPEG application.
We also note that, depending on the benchmark, the MGAP runs 10~102 times faster than both PMAP and PBB.

Figure-7: Maximum Link Bandwidth and Energy comparisons for M-JPEG
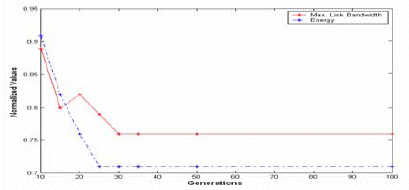
Figure-8: M-JPEG Encoder performance using NSGA-II
8. Conclusion
In this paper we have proposed a model for topological mapping of IPs/cores in a mesh-based NoC architecture. The approach uses heuristics based on multi-objective genetic algorithms (NSGAII) to explore the mapping space and find the pareto mappings that optimize maximum link bandwidth and energy consumption. The experiments carried out with three randomly generated benchmarks and a real application (M-JPEG encoder system) confirms the efficiency, accuracy and scalability of the proposed approach. Future developments will mainly address the definition of more efficient genetic operators to improve the precision and convergence speed of the algorithm. Evaluation will also be made of the possibility of optimizing mapping by acting on other architectural parameters such as routing strategies, switch buffer sizes, etc.
Reference
[1] A. D. Pimentel, S. Polstra, F. Terpstra, A. W. van Halderen, J. E. Coffland, and L. O. Hertzberger, “Towards efficient design space exploration of heterogeneous embedded media systemsâ€. In E. Deprettere, J. Teich, and S. Vassiliadis, editors, Embedded Processor Design Challenges: Systems Architectures, Modeling, and Simulation, volume 2268 of LNCS, Springer-Verlag, 2002, pp.7–73.
[2] C. A. Coello Coello, D. A. Van Veldhuizen, and G. B. Lamont, Evolutionary Algorithms for Solving Multi-Objective Problems, Kluwer Academic Publishers, New York, 2002.
[3] C. J. Glass and L. M. Ni, “The Turn Model for Adaptive Routingâ€, in Proc.19th Ann. Int’l Symp. Computer Architecture, May 1992, pp. 278-287.
[4] E. Zitzler and L. Thiele, “Multi-objective evolutionary algorithms: A comparative case study and the strength pareto approachâ€, IEEE Transactions on Evolutionary Computation, 4(3), Nov. 1999, pp. 257–271.
[5] J. Hu and R. Marculescu., “ Energy-aware mapping for tile-based NoC architectures under performance constraintsâ€, In Asia & South Pacific Design Automation Conference, Jan. 2003.
[6] J. Hu and R. Marculescu, “Exploiting the Routing Flexibility for Energy/Performance Aware Mapping of Regular NoC Architecturesâ€, in Proc. DATE’03, 2003, pp. 688-693.
[7] K. Lahiri, A. Raghunathan, and S. Dey, “Efficient Exploration of the SoC Communication Architecture Design Spaceâ€, in Proc. IEEE/ACM ICCAD’00, 2000, , pp. 424-430.
[8] K. Dev, Multi-Objective Optimization using evolutionary Algorithms, John Wiley and Sons Ltd, 2002, pp. 245-253.
[9] K. Srinivasan and Karam S. Chatha, “ ISIS : A Genetic Algorithm based Technique for Custom On-Chip Interconnection Network Synthesisâ€, Proceedings of the 18th International Conference on VLSI Design (VLSID’05),2005.
[10]Luca Benini and Giovanni De Micheli, “Networks on Chips: A New SoC Paradigmâ€, IEEE Computer, January 2002, pp. 70–78.
[11]M. R. Garey and D. S. Johnson, “intractability: a guide to the theory of NP- completeness.â€, Freeman and Company, 1979.
[12] N. Banerjee, P. Vellanki, and K. S. Chatha, “A power and performance model for network-onchip architectures â€, In Design, Automation and Test in Europe, Feb. 16–20, 2004, pp. 1250–1255.
[13] S. Kumar et al., “A Network on Chip Architecture and Design Methodologyâ€, in Proc. ISVLSI’02, April 2002, pp. 105-112.
[14] S. Murali and G. D. Micheli, “Bandwidthconstrained mapping of cores onto NoC architecturesâ€, In Design,Automation, and Test in Europe, IEEE Computer Society, Feb. 16–20 2004, pp. 896–901.
[15] T. Lei and S. Kumar, “A two-step genetic algorithm for mapping task graphs to a network on chip architectureâ€, In Euro micro Symposium on Digital Systems Design, Sept. 1–6, 2003.
[16] T. T. Ye, L. Benini, and G. D. Micheli, “Analysis of Power Consumption on Switch Fabrics in Network Routersâ€, in Proc. DAC’02, June, 2002, pp.524-529.
[17] William J. Dally and Brian Towles, “Route Packet Not Wires: On-Chip Interconnection Networksâ€, In Proceedings of DAC, June 2002.