
Awashesh Kumar, IIT Delhi
Abstract:
An ever increasing demand for execution speed and communication bandwidth has made the multi-processor SoCs a common design trend in today’s computation and communication architectures. Design and development of these systems with tight time to market and cost considerations makes it a challenging task. Simulation is a valuable tool for the designer in the various stages of system development. Performance analysis and tuning the system for realistic applications demand considerable simulation speed. Existing simulation kernels do not provide sufficient simulation speed, forcing the designers to simulate a part of the system or use scaled-down version of the applications. This paper presents the experimental results on distributed simulation for achieving needed simulation performance. It concludes by summarizing the necessary conditions for distributed simulation of multi-processor SoC to achieve higher simulation speeds compared to non distributed version.
Introduction
Consider simulating a shared memory multi-processor SoC with a control processor and DSP, peripherals, and shared memory as shown in Figure 1.
Typical simulation framework consists of Instruction Set Simulator (ISS) models for control processor and DSP, simulation models for bus, peripherals, and shared memory in C++ or SystemC. All these models are integrated and simulated under the control of a simulation kernel. The simulation kernel utilizes the services provided by the Operating System. This service hierarchy is depicted in Figure 2.
Typically a multi-core SoC, as shown in Figure 1, is simulated using a single simulation kernel as shown in Figure 2. As the number of concurrent processes in the simulated models increases (e.g., increase in number of SC_THREADs in SystemC code), overall simulation speed decreases. Resulting simulation speed will not be sufficient for executing realistic applications.
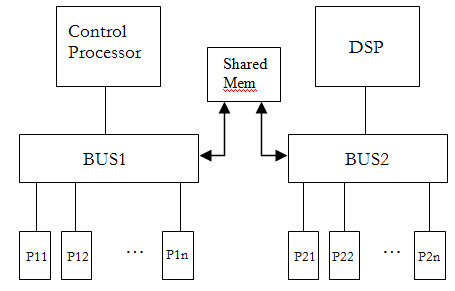
Figure 1. Multiprocessor SoC architecture
Lower simulation speeds limit the usability of the simulation model to a large extent. Realistic applications take too long to complete thus limiting the exploration space.
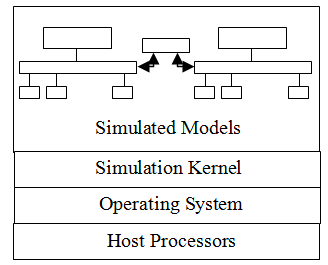
Figure 2. Simulation of SoC using single kernel
This paper presents the results of distributed simulation in achieving the needed simulation speed-ups. Experiments were carried-out using OSCI SystemC kernel [1].
1.1. Notion of concurrency in OSCI SystemC kernel
SystemC has constructs such as SC_THREAD and SC_METHOD providing the notion of concurrency. OSCI SystemC kernel implements the concurrency either using user-level code or using services provided by OS. By default, SC_THREADs are implemented using user level thread package QuickThreads [2]. The Quick thread library provides a co-operative thread execution model. This effectively limits the number of executing threads to one. With this limitation, at any given point in time, only one thread is active.
Recognizing this, one can experiment with pre-emptive thread library such as POSIX threads [3]. [4] shows that owing to the higher context switch overhead in POSIX threads, overall simulation speed may degrade in comparison to Quick threads for applications that have higher number of context switches.
Section 2 details the related work, section 3 details description on the distributed simulation. Section 4 gives brief introduction to MPI, section 5 details the experiment setup used, and section 6 details the results achieved. Section 7 details the effect of varying work load, section 8 analyzes the results. Section 9 concludes the paper and section 10 gives list of references.
2. Related work
The concept of using distributed computing to increase the simulation speed is not new. This section lists similar work and briefly looks at pros and cons of each approach. In general, we can classify the related work into two categories:
- Distribute simulation in a multi-processor computer
- Distribute simulation over a network of computers
2.1. Distribute simulation in a multi-processor computer
Automated concurrency re-assignment [4], describes effects of moving SystemC kernel from user-level threads to OS-level threads. Also, paper presents an algorithmic transformation of designs written in C++ based environments with concurrency reassigned along data flow in place of conventional hardware oriented flow. While this approach makes good use of multi-processors available, solution may not scale well for complex systems.
2.2. Distribute simulation over a network of computers
Geographically distributed SystemC model for IP/SoC [5] describes distributing SystemC models over network using sockets for communication. Using sockets limits the usefulness as the number of nodes increases.
SOAP Based Distributed Simulation Environment for System-on-Chip (SoC) Design [6], uses client-server model for distribution and uses Simple Object Access Protocol (SOAP) for communication. This model is mainly useful for verification purposes and not intended for simulation speed improvements.
Distributed simulation research is well established and several discrete event simulations have been presented in [7] and methods to manage parallel simulations [8][9]. These studies have been focusing on scientific computing applications. Application of these principles is presented in [10], where parallel version of the SystemC kernel is presented. While these approaches enable parallelization of application with minimal (or no) changes to the application, they require changes to simulation kernel, which may limit the applicability to open source simulators.
Parallelization of System-on-Chip (SoC) simulation over a network of computers [11] uses a custom C-language-based SoC exploration and simulation tool, Discrete Time Network Simulator (DTNS). Parallel entities communicate using either CORBA or TCP/IP. Using custom language may limit the usefulness of this approach.
2.3. Contribution
This paper outlines an approach that is:
- Independent of simulation kernel
- Applicable for both multi-processor computer and for network of computers
3. Distributed simulation
Multi-processor SoC is partitioned into parts than can be run concurrently on two work stations with independent SystemC kernels. Concurrently executing parts use Message Passing Interface (MPI) [12] for communication. To ease the process of partitioning, transactors for native API (like AHB, AXI) [13] to MPI and converse are built. This is illustrated in the Figure 3.
Partition point is found by analyzing the traffic in the system and the aim of this paper is to find the ideal ratio between computation and communication for the simulation to provide necessary speedups.
Transactors AXI2MPI and MPI2AXI convert the AXI protocol to MPI protocol and the converse respectively. Transactors also maintain the syncronization. For our experiments, we have considered functional simulation and transactors employ the blocking mechanism to maintain the order and synchronization. We believe that these transators can also be extended to other abstractions that involve cycle semantics.
Software development flow and the usage of the simulator largely remains the same.
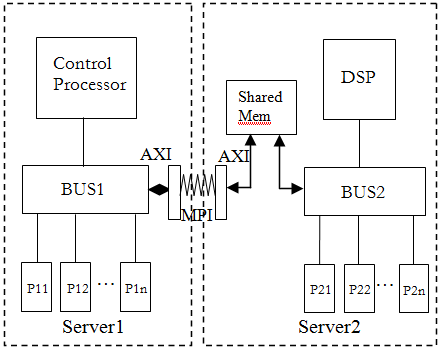
Figure 3. Distributed simulation of SoC over multiple workstations
4. Brief introduction to MPI
The Message Passing Interface Standard (MPI) is a message passing library standard based on the consensus of the MPI Forum, which has over 40 participating organizations, including vendors, researchers, software library developers, and users. The goal of the Message Passing Interface is to establish a portable, efficient, and flexible standard for message passing that will be widely used for writing message passing programs. As such, MPI is the first standardized, vendor independent, message passing library. The advantages of developing message-passing software using MPI closely match our design goals of portability, efficiency, and flexibility. MPI supports different modes of buffering and synchronization to be useful for wide range of scenarios. For further information on MPI please refer to [12].
5. Experimental setup
Finding the right partition point to break the SoC is critical, as this will ensure simulation speed-ups in spite of the increased communication overhead introduced by the MPI. To find the partition point it is essential that we study the effect of different computation and communication patterns on simulation speed. For this study we used the setup as shown in Figure 4.
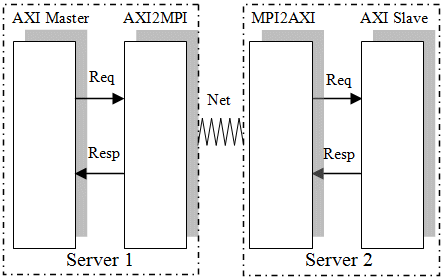
Figure 4. Experimental setup
AXI master implements a variable workload computation, i.e., the computation load is configurable by a workload parameter. General structure of the AXI Master is given bellow:
for (WL=1; WL<=MAX_WORK_LOAD; WL++) {
T1 = current_simulation_time;
for (j=1; j<=FACTOR*WL; j++) {
// Computation
}
// Comminication (Read/Write transactions)
T2 = current_simulation_time;
// Log total simulation time (T2-T1)
}
By varying FACTOR, we can vary the amount computation. AXI Slave services the requests from the master and also does some computation. Structure of the AXI slave is given bellow:
for (WL=1; WL<=MAX_WORK_LOAD; WL++) {
for (j=1; j<=FACTOR*WL; j++) {
// Computation
}
// Service master read/write requests
}
AXI2MPI transactor takes the read and write request from the AXI master and it converts it into a structure of MPI derived data type. MPI derived data structure is then transmitted using MPI blocking calls. MPI2AXI receives the MPI derived data structure and then converts it back to the AXI data structure and send the data to the AXI slave using AXI APIs. Sequence diagram illustrating this flow is given in Figure 5.
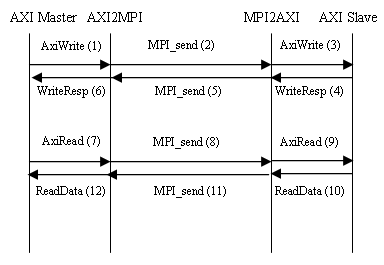
Figure 5. Sequence diagram for the AXI Read/Write calls.
5.1. Varying the work load in the experimental setup
To study the effect of workload variation on simulation speed, experimental setup is made configurable on work load and workload balance between AXI master and AXI slave. Slave module keeps doing some computation and at regular intervals of time samples for any requests from master. This interval is referred to as load slicing and is also configurable. For example, load slicing of 4 means that slave samples for every quarter of its computation. Load slicing should be chosen in such a way that the master doesn’t have to wait for slave’s availability. Synchronous MPI communication constructs ensure the data integrity between master and slave.
6. Results
Using the experimental setup, simulation speeds for various computation workloads are collected. Communication is kept constant to simplify the measurements. In order to quantify the gain in simulation speed over non-distributed version, same experiments were carried-out using single kernel solution (using only native AXI APIs).
Speedup is defined as the ratio of simulation speed on a single kernel solution and that of distributed simulation.
Workload is a measure of computational work being done by the simulator. For present experiments, 1 unit of work load is 0.3us of computation.
Figure 6 shows the simulation speed-up vs. computational load (with fixed communication). Workload is balanced on both maser and slave and slave employs load slicing of 4 (i.e., slave will sample every quarter of computation for any communication from master).
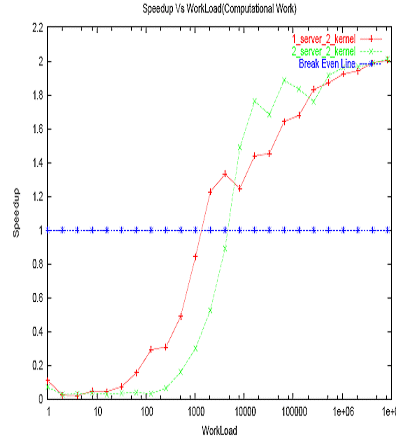
Figure 6. Simulation speedup vs. computational workload (slave load slicing is 4)
As can be seen in Figure 6, for small work loads distributed simulation speed (represented as 2_server_2_kenel) is far below the break even point (represented as break even line). As the workload increases, distributed simulation speed also increases and reaches the break even point. With further increase in workload, distributed simulation out performs non-distributed version and reached theoretical maximum of twice the simulation speed. Graph also shows the behavior when the simulation is run on single server using MPI with shared memory (represented as 1_server_2_kenel), which has similar behavior as 2_server_2_kenel but has much lesser break even point.
Figure 7 shows the simulation speed-up vs. computational load (with fixed communication). Workload is balanced on both master and slave and slave employs no load slicing (i.e., slave will sample after completing given computation for any communication from master). Graph also shows the behavior when the simulation is run on single server using MPI with shared memory (represented as 1_server_2_kenel in Figure 7).

Figure 7. Simulation speedup vs. computational workload (no slave load slicing)
Difference between two scenarios is in the maximum speedup achieved in either case.
7. Effect of varying master and slave work load
In order to study the effect of varying workload in master and slave (as opposed to balanced workload in both master and slave which was considered in previous section), work load factor in both master and slave were varied. Master and slave work load were chosen such that they sum up to a constant. Figure 8and Figure 9 plot the speedup with slave load slicing of 3 and 4 respectively.
It is interesting to note that if the total of master and slave work load is much above the work load at breakeven point, then good simulation speedup over the single kernel solution can be achieved.
8. Analysis
As expected for small workloads, the overhead of MPI communication slows down the simulation and single kernel simulation performs better than distributed simulation. But as the workload increases, communication overhead reduces and simulation speed-up increases. Work load of around 1200-1300 achieves break even with single kernel simulation speed. With further increase in workload, simulation speedup increases and reaches theoretical maximum of factor of 2 over single kernel simulation.
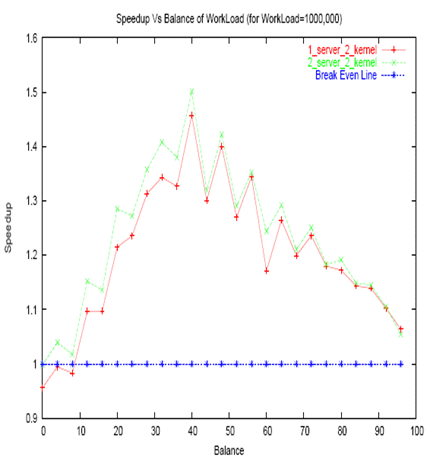
Figure 8. Effect of variation in balance of work load (slave load slicing of 3)
Single server setup with shared memory for MPI also follows similar curve but achieves break even point at much lesser workload as the communication overhead is less when compared to that of MPI over Ethernet.
Also, in case of varying workload, if the sum of the workloads in master and slave are kept higher than the workload at break-even point, then considerable speedups can be achieved.
Further we observe that:
- For the balanced workload; workload at break even is twice the communication delay
- For varying work load (but them sum to a constant); break even is achieved for workload that is greater work load at break even
9. Summary and future work
Paper demonstrates the distributed simulation experiment with MPI. Further it shows that it is possible to gain considerable simulation speedups using distributed simulation with necessary conditions. Paper also characterizes the break-even point.
With clear understanding of the break even point for achieving the simulation speedups we plan to work on automated distribution of SoC simulation.
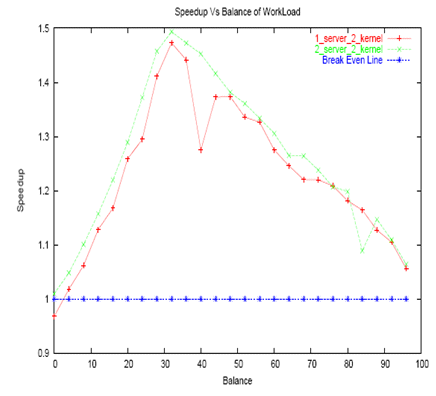
Figure 9. Effect of variation in balance of work load (slave load slicing of 4)
10. References
[1]. The Open SystemC Initiative (OSCI), SystemC Reference Manual.
[2]. D. Keppel. Tools and techniques for building fast portable thread packages. Technical Report UWCSE-93-05-06, Computer Science and Engineering, Univ. of Washington, May 1993.
[3]. T.Wagner and D. Towsley. “Getting started with posix threadsâ€. Technical report, Computer Science Department, Univ. of Massachusetts, Amherst, July 1995.
[4]. N. Savoiu, SK Sukla, and RK Gupta. “Automated concurrency re-assignment in high level system models for efficient system-level simulationâ€, proceeding of Design, Automation and Test in Europe Conference and Exhibition, 2002.
[5]. S. Meftali, J. Vennin and J. L. Dekeyser, “Automatic Generation of, Geographically Distributed, SystemC Simulation Models for IP/SoC Designâ€, Research Paper ©2004,IEEE.
[6]. S. Meftali, A. Dziri, L. Charest, P. Marquet and J. L. Dekeyser, “SOAP Based Distributed Simulation Environment for System-on-Chip (SoC) Design â€, Research Paper 2003, Universite des Sciences et Technologies de Lille ,France.
[7]. R. Fujimoto, “Parallel Discrete Event Simulation,†Communications of the ACM, Vol. 33, No. 0, Oct. 1990, pp. 30-53.
[8]. J. Misra, “Distributed Discrete-Event Simulation,†ACM Computing Surveys, Vol. 18, No. 1, Mar. 1986, pp. 39-65.
[9]. Y. M. Teo, et al., “Conservative Simulation Using Distributed-Shared Memory,†Proc. 16th Workshop on Parallel and Distributed Simulation, 2002, pp. 3-10.
[10]. Philippe Combes, et al, “A Parallel Version of the OSCI SystemC Kernelâ€, presented at 14th European SystemC Users Group Meeting.
[11]. J. Riihimäki, V. Helminen, K. Kuusilinna, and T. D. Hämäläinen, “Distributing SoC Simulations over a Network of Computersâ€, Proceedings of the Euromicro Symposium on Digital System Design (DSD’03), 2003 IEEE.
[12]. Peter S. Pacheco, “Parallel Programming with MPIâ€, Morgan Kaufmann Publishers Inc.
[13]. ARM, AMBA AXI Specification