
By Chien-Chun (Joe) Chou, Sonics, Inc.; Konstantinos Aisopos, EE Dept., Princeton University; David Lau, MIPS Technologies; Yasuhiko Kurosawa, Toshiba Corporation; and D. N. (Jay) Jayasimha, Sonics, Inc.
1 Introduction
Open Core Protocol (OCP) [1][2] is a common standard for Intellectual Property (IP)core interfaces. OCP facilitates IP core plug-and-play and simplifies reuse by decoupling the cores from the on-chip interconnection network and from one another. The OCP interface allows IP core developers to focus on core design without knowing details about the System-on-Chip (SoC) that the core might eventually be used in. Recently, numerous academic publications pointed out the benefits of hardware coherence in MultiProcessor SoCs (MPSoCs) [3][4][5], citing reasons such as enhanced performance versus software approaches, faster time-tomarket, flexibility, and ease of programming.
Enabling hardware cache coherence support at OCP cores requires the OCP interface to generate and receive additional coherence messages in order to invalidate cache lines cached at the core side or transfer cache lines and their ownerships between OCP cores. In addition, the protocol extension needs to be flexible enough to support different system-level coherence schemes such as any invalidate-based snoopy coherence scheme or any directory-based coherence scheme. Other possible challenges in the design of a cache coherent heterogeneous system include dealing with different sets of cache line states across initiator cores, different protocols, and allowing multiple cache-line sizes.
In the following sections, the concept of OCP coherence extensions is proposed. Moreover, a possible OCP-based coherence design utilizing the proposed OCP coherence extensions to support system-level cache coherence is also demonstrated.
2 Proposed Coherence Extensions to OCP
OCP enforces a point-to-point communication interface between two entities acting as the master and the slave of the OCP instance. Different types of communications can happen between the master and the slave of an OCP instance.
2.1.1 OCP Transfer and Transaction
An OCP dataflow communication (e.g., an OCP transfer) usually starts when the master presents a read request or a write request with data to the slave. The communication usually ends when the slave responds to the request presented to it, either by returning data to the master or by accepting the data sent from the master. One OCP data word is exchanged between the master and the slave in the above OCP transfer where the memory location of the data word is given by the master. An OCP burst transaction can include a set of transfers similar to the one mentioned so that multiple data words can be communicated between the master and the slave.
2.1.2 Example Cache Coherence Transaction
The need for separate coherence transactions and additional ports on OCP is motivated through an example. Since a memory cache line usually has a size of multiple OCP data words, it can be delivered between the master and the slave of an OCP instance by an OCP burst given the critical word’s address using a WRAP or XOR burst sequence. However, in a multiprocessor system where cache coherency among multiprocessor caches is maintained by hardware, the agent involved in a cache coherence transaction happening in the system can include the home of the cache line (e.g., memory), the latest owner (e.g., a processor core) of the cache line, many possible copy holders (e.g., many processor cores) of the cache line, and the processor core attempting to obtain the latest copy of the cache line into a specific state. It is straightforward to notice that all communication patterns that needed for completing the cache coherence transaction described are not covered by only treating each processor core as an initiator OCP core and utilizing the request and response dataflow between the master and the slave only..
For instance, an initiator processor core should be able to start a cache coherence transaction, to accept and answer to a cache line inquiry resulting from a cache coherence transaction, and to possibly return its latest cache line copy to the transaction’s originator. In other words, each processor core needs to (1) send coherent commands using the existing OCP interface (i.e., the master port1); (2) have an additional OCP slave port in order to receive cache inquiries and invalidations; (3) have a new OCP coherent state signal for answering cache inquiries; and (4) have a new OCP response to indicate the carrying of a coherent state without transferring cache line data words. Other capabilities can also be essential for each coherence transaction, such as: the identification scheme (for routing) used among OCP inquiry/invalidation ports mentioned above, and the distinction between a “self†cache line inquiry/invalidation and an inquiry coming from others, e.g., a “system†cache line inquiry/invalidation.
2.1.3 OCP Coherence Extensions
In order to support system-level cache coherence, such as in a directory-based MPSoC, the OCP 2.2 port needs to be extended with new coherent signals and signal encodings to deliver coherent transactions. From the system design point of view, each processor core with its caches and the directory module are now considered as a coherent initiator and a coherent target, respectively. In addition, a new OCP port, the OCP intervention port, is introduced and attached to each coherent initiator or target to allow coherent cores to probe and update each other coherent cores’ cache coherency states, as well as to transfer cache lines. Figure 1 shows a possible block diagram of a directory-based multiprocessor on-chip design using OCP and coherence extensions. The figure further illustrates roles played by the processor cores, the directory module, the memory sub system, and the I/O device – that is as coherent initiators, as coherent target and OCP initiator, as OCP target, and as OCP target, respectively. Note that each coherent initiator (e.g., a processor core) has an outgoing OCP coherence extensions (OCPce) port and an incoming OCP intervention (OCPi) port. On the other hand, a coherent target (e.g., a directory module) has an incoming OCPce port and an outgoing OCPi port.

Figure 1 Using OCP and Coherence Extensions in a Directory-Based Multiprocessor System Design
OCPce (Coherent Extensions) Port2
The OCPce port used by each coherent initiator is still able to issue regular OCP 2.2 read and write commands; in addition, the initiator can also use the extended interface to start cache coherence transactions. For instance, the OCPce port’s MCmd signal is extended to allow several new optional coherent command encodings, such as (just to mention a few):
- The cache-line read-for-ownership command (CC_RDOW),
- The cache-line read-for-shared command (CC_RDSH),
- The cache-line writeback command (CC_WB),
- The cache-line upgrade command (CC_UPG), and
- The cache-line invalidation command (CC_I).
Depending on which cache coherency protocol is used by the coherent initiator, only used coherent commands need to be enabled. Note that new coherent commands can be used only when the new OCP parameter, cohcmd_enable, is set to 1.
If the MESI protocol3 is used, when a coherent initiator, the originator of a read-for-shared coherent transaction, receives the cache line data words, the initiator has a choice to put its cached line in Exclusive (E) state or in Shared (S) state, depended on whether any other coherent initiator also has a shared copy of the same cache line. To enable this capability, a new SCohState signal is introduced allowing the slave of an OCPce instance (e.g., another coherent initiator) to suggest an installing state for the cache line targeted by the originating coherent initiator. Encodings for this SCohState signal include Invalid (I), Shared (S), Modified (M), Exclusive (E), and Owned (O). This optional SCohState signal can be turned on by setting the new OCP control parameter, cohstate_enable, to 1.
When a coherent initiator wants to upgrade a cached line from S state to M state using the CC_UPG command, for instance, it will not to receive any cache line data words, if it has them already. But, this originating initiator still needs to receive an acknowledgement indicating that all other coherent initiators’ shared cache line copies (if any) have been invalidated. A new OCP SResp signal encoding, “OKâ€, is added to allow a coherence ack message to be returned by the slave of an OCPce instance without transferring any data words. The new SResp encoding is allowed only when coherence commands are enabled.
OCPi (Intervention) Port4
The second OCP interface is called the intervention port because it is used to enforce systemlevel coherency by intervening. For instance, after a read-for-ownership coherent transaction is issued, the intervention interface of each of the coherent initiators (including the originator) can be used to find the existence and state of the targeting cache line. Each coherent initiator receiving the intervention request can decide what actions to take – e.g., invalidating its cache line copy and, if needed, passing ownership and data words of the dirty cache line back to the originator.
The intervention port is an OCP-like port and can be configured as a single-threaded, single request / multiple data (SRMD) interface with the following additional protocol rules and features:
-
Each intervention transfer is either a read-type transfer (i.e., cache line data words return from the slave of an intervention instance to the master) or a no-data transfer. In other words, the OCP MData signal and the datahandshake phase are never used.
-
Only coherence intervention commands for cached lines are encoded in the MCmd signal. Intervention commands (just to name a few) include the read-for-ownership intervention command (INTV_RDOW), the read-for-shared intervention command (INTV_RDSH), the writeback intervention command (INTV_WB), the upgrade intervention command (INTV_UPG), and the invalidation intervention command (INTV_I).
-
The MAddr signal field is used only to indicate the home memory location of the targeting cache line. Hence, for each intervention request, an identification (ID) signal field (such as the OCP MReqInfo signal) must be used to carry the ID number of the targeting coherent initiator. When the ID number of the coherent transaction’s originator is important, an additional sub field of the MReqInfo signal, which carries the originator’s ID for intervention requests, may be needed. Moreover, the SRespInfo signal may also be needed to carry the originator’s ID for intervention responses.
-
The OCP MReqInfo signal can also be used to carry a “self†intervention or “system†intervention indicator.
-
Like the OCPce port, a SCohState signal is used to carry the suggestion of an installing state for the targeting cache line. Possible coherent states are Invalid (I), Shared (S), Modified (M), Exclusive (E), and Owned (O).
-
Like the OCPce port, an “OK†encoding is added to the SResp signal. Table 1 summarizes the OCP2.2 signals (enabling a single-threaded, non-blocking SRMD OCP interface to transfer OCP bursts), the new intervention signals, and their corresponding new encodings and control parameters for the OCP intervention interface4.
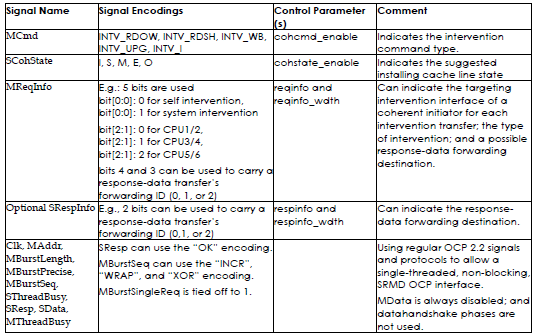
Table 1 OCP Intervention Interface Signals and Control Parameters
3 Coherence Transactions
Applying OCP and the OCP coherence extensions described in the previous section to the directory-based multiprocessor design shown in Figure 1 allow the system-level cache coherence to be enforced by hardware between all processor caches and the memory module. In the following sub sections, coherence transaction examples are used to illustrate how the system-level coherency can be maintained by utilizing the OCP extensions for coherence transactions issuing from the coherent initiator (i.e., the processor core).
Note that in the directory-based multiprocessor design, the MSI protocol is used by the multiprocessor caches and by the directory module. In addition, all OCP ports have the same data width and a cache line is assumed to equal to two OCP data words. Also, each OCP port (OCP, OCPce, or OCPi) is displayed with a request-side channel (for the request phase and, if applicable, the datahandshake phase) and a response-side channel (for the response phase) in all figures in this section.
3.1.1 Cache Write Back Transaction Flow
Figure 2 displays the high-level data flow for a coherent CC_WB transaction originating from the CPU 1/2 module. Note that the CPU 1/2 module has the dirty copy (in M state) of the cache line that the module wants to write back to memory initially. Also, since none of the OCPce ports for the CPU 3/4 module and the CPU 5/6 module will be involved in this coherent transaction, they are not displayed in the figure for simplicity.

Figure 2 CC_WB Transaction Flow
Since it is not easy to capture all communications involved in a coherence transaction using the block diagram as shown in Figure 2, we will use space-time diagram instead. For instance, Figure 3 is a space-time diagram displaying the CC_WB transaction’s causality among requests and responses occurred on OCPce ports, OCPi ports, and OCP ports.
Conventions used in all space-time diagrams in this section include: (1) time goes forward from top to down and the absolute timing differences between messages bear no meaning here; (2) coherent initiators, coherent targets, and legacy OCP cores are spread in space from left to right with their labels on top; (3) vertical arrow lines associated with each core (e.g., CPU 1/2, Directory, CPU 3/4, CPU 5/5, or Memory) indicates whether a port is an output port or an input port for the core; in addition, solid vertical arrowed lines are for OCPce or OCP ports and bolded vertical arrowed lines are for OCPi intervention ports; (4) a dashed arrow line between two solid vertical arrowed lines represents an OCPce/OCP request or response being sent from the first port to the second port. Each dash line is labelled with its request or response attributes; (6) a dashed arrow line between two bold vertical arrowed lines represents an intervention port request or response being sent from the first port to the second port; (7) a horizontal solid arrow line, which goes between ports of a core, tells the dependency between receiving of requests or responses and sending of responses or requests at the core; and (8) state changes for local caches and the directory are described.
For instance, Figure 3 is used to illustrate the following:
- For CPU 1/2, after it issuing a CC_WB main port request and two datahankshake phases (MData0 and MData1), it will receive a self INTV_WB intervention request on its intervention port OCPi0 and after the CPU responding with a intervention port response (SResp OK and SCohState of I), it will eventually receive an OCPce0 port SResp to indicate the completion of it CC_WB transaction (and the cache line state goes to I).
- On the other hand, the Directory module not only sends a self intervention request back to CPU 1/2 (indicated by CID0), it also writes back the cache line (MData0 and MData1) to its home Memory module using legacy ports OCP3 and OCP4.

Figure 3 CC_WB Transaction Flow
3.1.2 Read for Share and Dirty at a Master Cache
Figure 4 displays the space-time data flow for a coherent CC_RDSH transaction originating from CPU 1/2 where the dirty data is located at the CPU 3/4 module’s cache. Note that the Directory module knows that the latest dirty cache line is stored at the cache of the CPU 3/4 module (CID1). Therefore, in addition to return a self intervention request back to the originating CPU 1/2 module, it also sends a system intervention request from the OCPi3 port to the CPU 3/4 module’s intervention OCPi1 port (the request’s MReqInfo signal carries “system†and CID1). After receiving the intervention INTV_RDSH request, the CPU 3/4 module not only changes its cache line state from M to S but also returns the latest cache line data words (SData0 and SData1) to the directory before being copied and sent to both the CPU 1/2 module and the Memory sub system using OCPce3 and OCPce0 ports, and OCP3 and OCP4 ports, respectively.
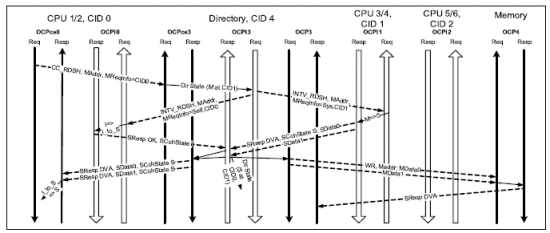
Figure 4 CC_RDSH and Dirty at Cache
3.1.3 Read for Ownership and Dirty at a Master Cache
Figure 5 displays the space-time data flow for a coherent CC_RDOW transaction originating from CPU 1/2 where the dirty data is located at the CPU 3/4 module’s cache. The communication pattern is similar to Figure 4 except that the cache installing states are different and there is no need to copy the cache line to memory.
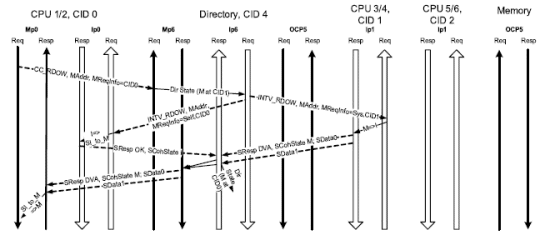
Figure 5 CC_RDOW and Dirty at Cache
3.1.4 Cache Upgrade When the Cache Line is Shared by Multiple Masters
Figure 6 displays the space-time data flow for a coherent CC_UPG transaction originating from CPU 1/2 where the cache line is shared at the CPU 1/2 module’s cache, the CPU 3/4 module’s cache, and at the CPU 5/6 module’s cache. Therefore, after the Directory receives the CC_UPG request, it sends three intervention requests, a self intervention request to the CPU 1/2 module, two INTV_UPG system intervention requests to the CPU 3/4 module and the CPU 5/6 module each.
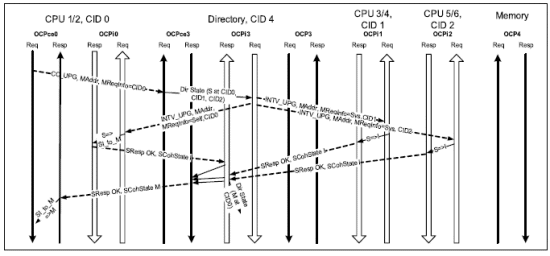
Figure 6 CC_UPG and Shared at All Caches
3.1.5 Cache Flush or Purge and Shared at Master Caches
Figure 7 displays the space-time data flow for a coherent CC_I transaction originating from CPU 1/2 where the cache line is shared at the CPU 3/4 and CPU 5/6 modules’ caches.

Figure 7 CC_I and Shared at Others
4 Conclusions
OCP Coherence extensions suitable for MPSoC architectures have been proposed. This article gives the motivation for this work and includes a description of a few commands. The use has been illustrated with a directory-based on-chip multiprocessor design example. Model checking technique has also been used to verify protocol correctness for the entire state space of a directory-based application and a snoopy-bus-based application. A complete proposal including new signals, new signal encodings, new protocol rules, and new control parameters were submitted to the OCP-IP Specification Working Group in 2008, and will be released as part of OCP v.3.0. in the first half of 2009. We thank Drew E. Wingard, Wolf-Dietrich Weber, Steve Krueger, Sanjay Vishin, and Robert Nychka for their guidance and contributions to the proposed OCP coherence extensions.
References
1. OCP International Partnership: Open Core Protocol Specification, Release 2.2, Jan. 2007.
2. W.-D. Weber. Enabling reuse via an IP core-centric communications protocol: Open Core Protocol. In Proc. IP 2000 System-on-Chip Conference, pages 217 – 224, March 2000.
3. T. Suh, D. Kim, and H. S. Lee. Cache coherence support for non-shared bus architecture on heterogeneous MPSoCs. In Proc. Design Automation Conf., pages 553 – 558, June 2005.
4. T. Shu, H.-H. S. Lee, and D. M. Blough. Integrating cache coherence protocols for heterogeneous multiprocessor systems, part 1. IEEE Micro, 24(4):33 – 41, July 2004.
5. M. Loghi, M. Poncino, and L. Benini. Cache coherence tradeoffs in shared-memory MPSoCs. ACM Transactions on Embedded Computing Systems, 5(2):383 – 407, May 2006.
6. Bhadra, J.; Trofimova, E.; Abadir, M.S. Validating Power Architecture™ Technology-Based MPSoCs Through Executable Specifications. Very Large Scale Integration (VLSI) Systems, IEEE Transactions on 16(4):338 – 396, April 2008.
7. http://www.mips.com/products/processors/32-64-bit-cores/mips32-1004k
8. http://www.arm.com/products/CPUs/ARMCortex-A9_MPCore.html
9. AMBA AXI Protocol v1.0 Specification, ARM, June, 2003.
10. Virtual Socket Interface Alliance. Virtual Component Interface Standard Version 2 (OCB 2 2.0), April 2001.
11. I. Mackintosh, OCP Chairman and President. MPSoC and ‘The Vision Thing’. EDA Tech Forum Journal, 4(3):6 – 7, September 2007.
1
We will use and treat the terms: “OCP interface†and “OCP port†interchangeable in the article.
2 The final complete set of new signals, new signal encodings, new protocol rules, and new control parameters for the OCP coherence extensions were proposed to the OCP-IP Specification Working Group in 2008 and are included in OCP v.3.0 schedule for release in the first half of 2009. Content listed in this sub section covers only a portion of the initial proposal.
3 In this cache coherency protocol, each cached line can be in Modify (the only copy), Exclusive (the only copy), or Shared state; otherwise (Invalid), the cache line is not cached and is stored in the home memory.
4 A complete set of new signals, new signal encodings, new protocol rules, and new control parameters for the OCP intervention port will be proposed to the OCP-IP Specification Working Group in 2008. Content listed in this sub section covers only a portion of the initial proposal.