
G.Tian and O.Hammami, ENSTA
Abstract:
Multi-core are emerging as solutions for high performance embedded systems. Although important work have been achieved in the design and implementation of such systems the issue of synchronization mechanisms have not yet been properly evaluated for these targets. We present in this work synchronization performance evaluation results on a 16PE NOC based multi-core which we designed and implemented on a single FPGA chip. All reported results come from actual execution and show hybrid synchronization mechanisms best fit the multi-core configurations.
I. INTRODUCTION
Multiprocessor system on chip are emerging as potential solutions for high performance embedded systems [1-2] [15-22]. Although hardware design of multi-core remains a complex challenge it is essential to evaluate the capability of software tools to exploit these devices. This paper investigates optimized synchronization techniques for shared memory on-chip multiprocessors (CMPs) based on network-on-chip (NoC). Parallel software implementation involves complex tradeoffs among them partitioning and low balance, overhead and granularity of communication, working set and locality of references and synchronization [3]. Poor synchronization primitives and hardware may greatly impact parallel program performance. We present in this paper a performance analysis on hardware support for synchronization involving the benefit of : (1) a dedicated synchronization NOC (2) lock placement in external memory (e.g. DDR2) or on-chip memory (3) basic blocking primitive vs LL-SC primitive all in the framework of an OCP-IP based single FPGA implementation of a 16PE NOC. Although several studies have adressed synchronization issues [4-8] in embedded multiprocessors to the best of our knowledge this is the first paper to address synchronization issues on actual hardware within the framework of a 16PE with NOC single FPGA implementation. The paper is organized as follows: In section II we describe our 16 PE NOC based Multi-core architecture. Section III presents the OCP-IP based synchronization mechanisms while Section IV describes the synchronization performance evaluation experiments. Finally we give our conclusion in section V.
II. MULTI-CORE ARCHITECTURE
For our experiments we used a 16PE multi-core we designed [9, 10]. The block diagram of the overall multi-core architecture is shown in Figure 1.

Figure 1: general overview of the FPGA implemented architecture
The multi-core system integrates 16 Xilinx MicroBlaze Processing Elements (PE) [11] based tiles. Each tile is a powerful computing system with 64KByte local memory that can independently run its own program code.
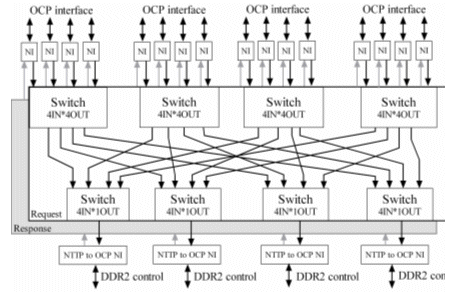
Figure 2: general view of the DATA NOC architecture

Figure 3:general view of the Synchro NOC architecture
PE Tiles are connected to Data-NoC (Network on Chip) and Synchronization-NoC through OCP-IP interfaces [12]. One 64KBytes shared on-chip memory is attached to the synchronization NoC, which establishes a synchronization media for the 16 PE tiles. Data NoC is connected to four DDR2 controllers, which in turn connect to four off-chip 256MBytes DDR2 memory (totaling 1 GBytes).One of PE tiles is also connected to a PCI express interface for the off-chip communication purpose. The on-chip network connection system is developed with the Packet Transport Units (PTU) from the Arteris Danube library [13]. These PTUs build the packet transport portion of the NoC, which is comprised of a request network and a response network. All the PTUs adopt NoC Transaction and Transport Protocol (NTTP) which is a three-layered approach comprising transaction, transport and physical layers.

Figure 4: Block diagram of Alpha-Data FPGA platform card ADPe-XRC-4
The 16PE multi-core have been implemented on a single Xilinx FPGA Virtex-4 FX140 chip [11] and executes on an Alpha-Data board [14] described figure 4.
III. OCP-IP BASED SYNCHRONIZATION NOC DESIGN
There are 3 major steps in a synchronization event: (1) acquire method, (2) waiting algorithm (3) release method [3]. There are 2 main choices for the waiting algorithm: busy waiting and blocking. Busy-waiting means that the process spins in a loop that repeatedly tests for a variable to change its value. Blocking the process does not spin but simply blocks itself and releases the processor if it finds that it needs to wait. Busy-waiting is likely to be better when the waiting period is short whereas blocking is better if the waiting period is long. Synchronization mechanisms should present: (1) low latency, (2) low traffic, (3) scalability (4) low storage cost and (5) fairness. Two common ways of implementing synchronization are: read-modify-write and LL-SC. The load-linked store-conditional OCP protocol supports two ways of synchronization among OCP masters. The first one is Locked synchronization, which is an atomic set of transfers. OCP initiator use the ReadExcusive(ReadEX) command and Write or WriteNonpost command to perform a read-modify-write atomic transaction.

Table 1: OCP MCmd
In our system the NTTP protocol translates such accesses by inserting control packets, Lock and Unlock, on the request flow.
The NIU sends a Lock request packet when it receives the ReadEX command. The Lock request locks the whole path to the NTTP slave. Then a LOAD request packet read the data of NTTP slave. OCP master modifies the data and sends to slave by Write or WritreNonPost command. When the NIU receives the Write command, it write the data to required NTTP salve by a STORE request packet then release the NoC by Unlock request packet.
The other competing OCP masters cannot access the locked location, until the Unlock packet is sent. Such a mechanism is efficient for handling exclusive accesses to a shared resource, but can result in a significant performance loss when used extensively.
Barrier synchronization mechanism can be implemented on top of OCP synchronization mechanism.
IV. SYNCHRONIZATION PERFORMANCE EVALUATION EXPERIMENTS
We have conducted synchronization performance evaluation experiments. Although some efforts have been made for the benchmarking of NOC very little effort have been made regarding the benchmarking of NOC for synchronization.
A. Synchronization Micro-benchmarks
NOC benchmarking is an emerging issue and although several proposals have been made NOC benchmarking for synchronization remains an open issue. We use the same approach as [3] through synchronization micro-benchmarks.

Figure 5: Synchronization Micro-benchmarks
B. LL-SC vs Blocked Synchronization with DDR on Data NOC
In a first step we evaluate the performance of blocked synchronization versus LL-SC when the lock is placed in the DDR with no caching.

Figure 6: Synchronization access to DDR
Processors attempt to access the lock variable in the DDR through the OCP interface and the network on chip.

Figure 7: Performance Comparison Results
The LL-SC synchronization take more time than the blocked synchronization for all the configurations. The fact that the lock is not cached does not place LL-SC at an advantage.
C. Blocked Synchronization on Dedicated Synchronization NOC/ DDR2 vs. BRAM
In a second step synchronization is conducted through a dedicated NOC with access to lock variable placed in an on-chip memory (BRAM).

Figure 8: Multiprocessor architecture without synchronization NOC

Figure 9: Performance Comparison Results
Clearly, blocking on BRAM with dedicated NOC reduces by 40% the synchronization time for 15 processors. It is expected that the mechanisms scales well.
D. Discussion
The overall results show the superiority of the blocked mechanism in the dedicated synchronization NOC with BRAM over LL-SC with BRAM or blocked with DDR.

Figure 10: Performance Comparison Results
V. CONCLUSION
Multiprocessor on chip design and implementation represents a significant investment. Resulting efficiency of this multiprocessor system on chip is therefore essential. Synchronization mechanisms play a fundamental role in this regard and careful attention is necessary for the hardware implementation of these synchronization mechanisms. We have conducted performance experiments on a single chip embedded multiprocessor and it clearly appears that a dedicated synchronization NOC with dedicated on-chip memory for lock variable is the best solution. Industrial implementation of MPSOC should take into account considerations of area/performance tradeoff of synchronization.
REFERENCES
[1] A.A. Jerraya and Wayne Wolf , “Multiprocessor Systems-on-Chipâ€, Morgan Kaufman Pub, 2004
[2] X.Li, O.Hammami, “Fast Design Productivity for Embedded Multiprocessor Through Multi-FPGA Emulation The case of a 48-way Multiprocessor with NOCâ€, IP 08 Grenoble France Dec. 2008
[3] David Culler , J.P. Singh , Anoop Gupta Parallel Computer Architecture: A Hardware/Software Approach, Morgan Kauffman, 1998.
[4] Gai, P.; Lipari, G.; Di Natale, M.; Duranti, M.; Ferrari, A.; Support for multiprocessor synchronization and resource sharing in system-on-programmable chips with softcores SOC Conference, 2005. Proceedings. IEEE International 25-28 Sept. 2005 Page(s):109 – 110 (4)
[5] Monchiero, M.; Palermo, G.; Silvano, C.; Villa, O.;Efficient Synchronization for Embedded On-Chip Multiprocessors Very Large Scale Integration (VLSI) Systems, IEEE Transactions on Volume 14, Issue 10, Oct. 2006 Page(s):1049 - 1062
[6] Brandenburg, B.B.; Calandrino, J.M.; Block, A.; Leontyev, H.; Anderson, J.H.; Real-Time Synchronization on Multiprocessors: To Block or Not to Block, to Suspend or Spin? Real-Time and Embedded Technology and Applications Symposium, 2008. RTAS '08. IEEE 22-24 April 2008 Page(s):342 - 353
[7] Fide, S.; Jenks, S.;Architecture optimizations for synchronization and communication on chip multiprocessors Parallel and Distributed Processing, 2008. IPDPS 2008. IEEE International Symposium on 14-18 April 2008 Page(s):1 - 8
[8] Ono, Tarik; Greenstreet, Mark;A modular synchronizing FIFO for NoCs Networks-on-Chip, 2009. NoCS 2009. 3rd ACM/IEEE International Symposium on 10-13 May 2009 Page(s): 224 - 233
[9] Z.Wang, PhD Thesis, “Design and Multi-Technology Multi-objective Comparative Analysis of Families of MPSOCâ€, Nov. 2009, ENSTA ParisTech (9)
[10] Z. Wang, O. Hammami, “A Twenty-four Processors System on Chip FPGA Design with On-Chip Network Connectionâ€, IP SOC 2008, France.
[11] Xilinx www.xilinx.com (11)
[12] OCP-IP OCP-IP Open Core Protocol Specification www.ocpip.org
[13] Arteris S.A http://www.arteris.com/
[14] Alpha-data ADPe-XRC-4 FPGA Alpha-data
[15] ARM 11 MPCore
[16] MIPS32® 1004K™ Core
[17] S.Shibahara, M.Takada, T.Kamei, K. Hayase, Y.Yoshida, O. Nishii, T. Hattori, SH-X3: SuperH Multi-Core for Embedded Systems, Hot Chips 19th, Aug. 19-21 2007, Stanford, USA.
[18] 16. M.Butts, A.M.Jones, TeraOPS Hardware & Software: A New Massively-Parallel, MIMD Computing Fabric IC, Hot Chips 18th, Aug. 20-22 2006, Stanford, USA.
[19] 17. Texas Instruments Multicore Fact Sheet SC-07175
[20] 18. Texas Instruments TMS320C6474 Multicore DSP SPRS552 – Oct. 2008
[21] 19. Texas Instruments TMS320VC5441 Fixed-Point DSP data manual SPRS122F – Oct. 2008
[22] 20. QorIQâ„¢ P4080 Communications Processor