
Joseana Fechine, Lucas Paixão, Adalberto Júnior, FabrÃcio Melo, Sérgio Espinola
Center of Electrical Engineering and Informatics – CEEI /
Federal University of Campina Grande – UFCG
Abstract:
Alphanumeric passwords, identification via either chip cards or biometric parameters as iris pattern, fingerprints and voice are used to control access to confidential information and to restricted areas as well as to several types of automated money transactions. This paper aims at presenting an IP core whose purpose is to perform real-time speaker verification. The IP core can be used as part of a system to check if the speaker is really the one (he or she) who claims to be. For each speaker, the IP core needs a codebook which is obtained by off-line training. Linear Prediction Coding (LPC) and Vector Quantization (VQ) techniques are employed. The IP core was designed to process the signal in real time, meaning that, as soon as the IP core has gathered enough data to reach a certain confidence level, it will output its decision.
I. INTRODUCTION
Speech is a natural means of communication available to human beings. In a short conversation between two people, an individual can identify their age, gender and whether the language spoken by them is familiar or not. The person can also infer a series of other characteristics only by hearing someone's voice, such as: his/her emotional and health states, socioeconomic group, region of birth, etc. As a result of this, the Speech Related Scientific Community has been attempting to promote the speech man-machine communication over the last decades in order to satisfy the demand on both speech and speaker automatic recognition systems, as well as on speech synthesis systems [1-4].
For embedded battery-driven systems, such as a cellular telephone, the development of speech based applications must also take into account requirements such as low power consumption and reduced size [5-8].
II. DEVELOPMENT METHODOLOGY
The SPVR implementation was accomplished using two methodologies: one focused on the development of soft IP core, named ipProcess [9], and another for functional verification, named Brazil-IP Verification Methodology (BVM). BVM is a reformulation of VeriSC [12] and it is implemented in SystemVerilog language with the concepts and libraries of Open Verification Methodology (OVM).
Presently, 65% of IP cores do not succeed in their first silicon prototyping. 70% of these cases occur due a badly designed functional verification [10]. Any problem that escapes this stage may not be detected in the prototyping phase and will emerge only after the first silicon is integrated [11]. Thus, efforts are needed for the functional verification in order to avoid future inconsistencies during the project. The development flow is depicted in Fig. 1.
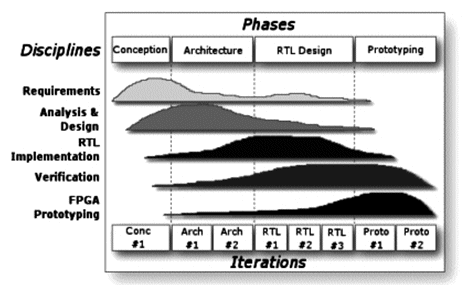
Figure 1: ipProcess development flow
Requirements: specification of the Hardware and the Functional Verification. The first is an analysis and of a documentation of requirements, essentials for the conception process. The second describes functionalities to be verified, stimuli to be used and coverage measurements.
The specification must have a high level of abstraction, without decisions about the implementation of the functionality in terms of the target architecture (software or hardware) adopted [12].
Analysis and Design: consists of the Testbench implementation. Pseudo-random stimuli are generated to be sent to the DUV, whose outputs are compared with the expected ones, provided by an ideal model, called Reference Model (RM). The RM is implemented in SystemVerilog. In BVM, the RM can be used to create a signal-level replacement of the DUV, without the need of extra code that would not be used for the final Testbench.
Implementation: characterized by the implementation of the Register Transfer Level (RTL) code, written in System Verilog.
Verification: DUV is inserted into the testbench; debug and simulation are performed until the coverage specified in the Functional Verification Specification is reached.
Prototyping: includes the Synthesis, both logic and layout synthesis are included, first for Field-Programmable Gate Array (FPGA) and then for silicon. Post-synthesis simulation resembles the functional verification phase. The difference is that the DUV is replaced by the netlist and it considers the delays of logic gates and wires.
III. ARCHITECTURE
SPVR is divided in six blocks and it is responsible for the speaker verification in real time. The training phase will be performed off-line by software. In Fig. 2, the architecture of the IP core is illustrated.
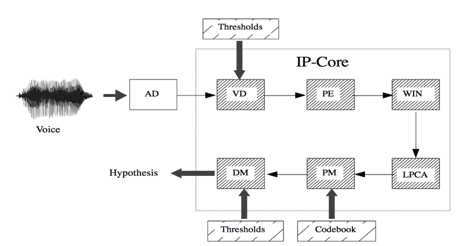
Figure 2: Architecture of SPVR
All functional blocks were implemented as finite state machines to reduce power consumption.
In the speaker verification task, as described previously, a preprocessing of voice signal is necessary. Preprocessing step is compound of: endpoints detector, preemphasis filter and signal windowing.
Voice Detector (VD) eliminates audio samples of noise or silence. This block must be sufficiently robust to deal with different noisy environments. This is a mechanism to avoid the processing of useless audio samples, increasing verification efficiency and reducing power consumption.
The detection is based on the energy of the voice signal frames (with duration of approximately 5ms) and on time restrictions. If the energy value is higher than a threshold (defined before the training phase and obtained by an empiric way), it starts counting the number of consecutive frames; when the number is equal to a start time threshold, the beginning of voice is found. To encounter the end, the process is similar; however the search is for frames with energy value lower than the threshold and with number of consecutive frames equal to an end time threshold, as depicted in Fig. 3.
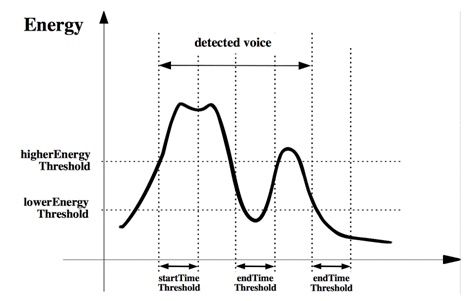
Figure 3: Behavior of VD
The next block, Preemphasis (PE), is responsible for the preemphasis filtering of voice signal. This is a filter of finite duration impulse response (FIR), which objective is to attenuate the signal components of low frequency, preventing numerical instability and minimize effects of glottis and lips [15]. In this article, Eq. 1 [14] was used, where α parameter is 0.9375 and it is called preemphasis factor:
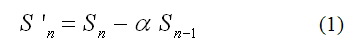
The last block of preprocessing step is the Windowing (WIN). The voice signal is windowed in frames as described in Fig. 4. The segments are selected according to stationary limits, thereby, time intervals that the statistics characteristics of the signal do not vary with time [1]. The type of window used in this case is the Hamming Window (Eq. 2),
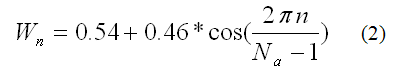
which gives more emphasis to samples in the middle of frame. The segmentation is done with a superposition of 50% to reduce the discontinuity and to use all the audio samples with a similar intensity.
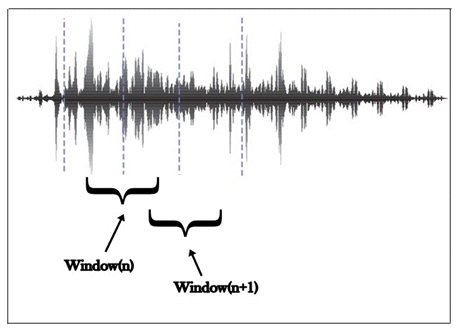
Figure 4: Windowing of signal voice
Linear predictive coding (LPC) is one of the simpler speech analysis techniques and can be used for encoding speech at a low bit rate. The basic idea behind LPC is that a speech sample can be approximated as a linear combination of past speech samples. By minimizing the sum of the squared differences, over a finite interval, between actual speech samples and the linearly predicted ones, a unique set of predictor coefficients can be determined. The linear prediction provides a method for estimating the parameters that characterize the linear time-varying system [1]. The block responsible for this task, in SPVR, is the Linear Prediction Coding Analysis (LPCA).
It was preferred to use the LPC coefficients instead of the others, for example, Mel-frequency cepstral coefficients, because they are effective speaker verification and decrease the complexity of the system.
Among the methods for determination of LPC coefficients, Autocorrelation was used. For each frame received from WIN, a vector with twelve coefficients is obtained, based on Levison-Durbin recursive procedure [16-17].
The Pattern Matching block (PM), during training phase, is responsible for analysis of LPC coefficients with respect to a set of ideal vectors, called codebook - a representation of speaker's vocal tract. This set is structured in matrix form of sixty-four vectors, with twelve coefficients each. The codebook is generated utilizing the vector quantization (VQ) technique with Linde–Buzo–Gray (LBG) algorithm [18] in the training phase.
The codebook of the speaker to be verified by SPVR needs to be input into PM before the corresponding audio samples. Therefore, each output vector from LPCA will be compared with each of the sixty-four vectors from codebook, getting the minor distance between them, based on the equation of mean square error, according to:
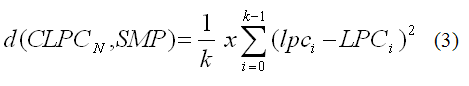
The last module is the Decision Maker (DM). It is responsible for a decision based on the average of distances received from PM and the distances thresholds. The threshold must be supplied to SPVR, in four values; two of them are used at running time, called “runningThresholdsâ€, while the others - “finalThresholds†- are used if there is time out at seven seconds, the maximum time (equivalent to 703 distances) to the system make a decision. In Figure 5 is shown the functionality of DM. For each new distance received from PM, the module recalculate the average, and compares with the running thresholds, if this average is lower than lowerRunningThreshold (T1), the system respond with a “Accepted†decision. If the average is higher than upperRunningThreshold (T4), the system response is “Rejectedâ€, else the system waits for more distances. When the module receives 703 distances, and the media of them continuous between the running thresholds, it is compared with the final thresholds. If the average stays between upperFinalThreshold (T3) and lowerFinalThreshold (T2), the system respond with “Unknownâ€.
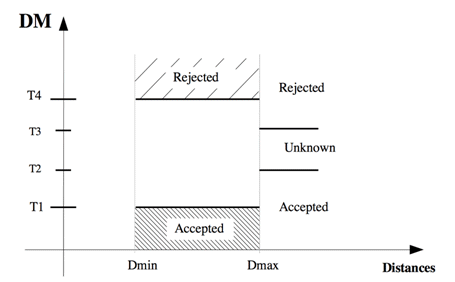
Figure 5: Behavior of DM
IV. RESULTS
The SPVR Design was prototyped using the Altera DE2 development and educational board to demonstrate the effectiveness of the proposed architecture. It was synthesized using the Quartus II 9.1 Build 222. Table 1 summarizes the compilation results.
TABLE I. Compilation Results

The audio codec Wolfson WM8731 provides a sample rate of 44.1 kHz [18] but we reduce it to 11025Hz calculating the arithmetic average for each four samples.
Synopsys tools have been used and the final netlist was generated by Design Compiler. The layout is in development in IC Compiler, working with the XFAB 0.35μm technology, 4 metal levels, approximately 40 mm² de core area without pads and 3.3V of voltage. A 4Kx16 bit RAM was employed for VD module.
V. CONCLUSION
Compared to traditional systems, the IP core for speaker verification - SPVR - comprises a viable solution to the security context by providing not only greater reliability, as well as facility of reuse and, consequently, fast incorporation to other supplementary systems, a fact that is really relevant in the modern world. The succeed chip implementation and its high hit rate demonstrate the effectiveness of the design methodologies adopted. The entire digital signal processing demanded was part of the chip development, which eliminates the necessity of external signal processors and makes the SPVR a robust and a self-sufficient hardware for collaborative users.
References
[1] Rabiner, L. R.; Schafer, R. W. (1978), Digital Processing of Speech Signals. Prentice Hall, Upper Saddle River, New Jersey.
[2] DODDINGTON, G. R. (1985), Speaker Recognition – Identifying People by their Voices. Proceedings of the IEEE, v. 73, n. 11, p. 1651-1664
[3] VASSALI, M. R.; DE SEIXAS, J. M.; ESPAIN, C. (2000), Reconhecimento de Voz em Tempo Real Baseado na Tecnologia dos Processadores Digitais de Sinais. In: XVIII Simpósio Brasileiro de Telecomunicações.
[4] MINKER, W.; BENNACEF, S. (2004), Speech and Human-machine Dialog. Boston, Kluwer Academic Publishers.
[5] LIN, E. (2003), A First Generation Hardware Reference Model for a Speech Recognition Engine. Masterthesis – School of Electrical and Computer Engineering, Carnegie Mellon University, Pittsburgh.
[6] KRISHNA, R., MAHLKE, S., AUSTIN, T. (2004), Memory system design space exploration for low-power, real-time speech recognition. Proceedings of the 2nd IEEE/ACM/IFIP international conference on Hardware/software codesign and system synthesis, p. 140 – 145.
[7] IBNKAHLA, M. (2005), Signal Processing for Mobile Communication Handbook. Florida: CRC Press.
[8] NEDEVSCHI, S., PATRA, R. K., BREWER, E. A (2005), “Hardware Speech Recognition for User Interfaces in Low Cost, Low Power Devicesâ€. Proceedings of the 42nd annual conference on Design automation, p. 684 – 689, San Diego, California, USA.
[9] LIMA, M., Aziz, A., Alves, D., Lira, P., Schwambach, V., Barros, E. (2005), ipPROCESS: Using a Process to Teach IP-core Development.IEEE, 0-7695-2374-9/05.
[10] DUEÑAS, C. A. (2004) Verification and test challenges in SoC designs. Invited Talk, September.
[11] M.Brunelli, L. Battú, A. Castelnuovo, and F. Sforza. (2001), Functional verification of an hardware block using vera. Synopys Users Group.
[12] SILVA, K. R. G. Uma metodologia de Verificação Funcional para Circuitos Digitais. (2007), 119 p. Tese - Universidade Federal de Campina Grande.
[13] BERGERON, J. (2003) Writing Testbenches: Functional Verification of HDL Models. 2nd Edition. Kluwer Academic Publishers, Norwell, MA, USA.
[14] FECHINE, J. M. (2000), Reconhecimento Automático de Identidade Vocal Utilizando Modelagem HÃbrida: Paramétrica e EstatÃstica, Tese de Doutorado, Pós-Grduação em Engenharia Elétrica, Universidade Federal de Campina Grande.
[15] Pegorago, T.F. (2000), Robusts Speech Recognition Algorithms for Speaker Verification. 101 f. Dissertation Electrical Enginnering – Campinas State University, Campinas,
[16] VIEIRA, M.N. (1989), Módulo Frontal para um Sistema de Reconhecimento Automático de Voz. Dissertação – Universidade de Campinas.
[17] SILVA, A.J.S. (1992), Quantização Vetorial: Aplicações a um Vocoder LPC. Dissertação - Universidade Federal da ParaÃba.
[18] Linde, Y., Buzo, A., & Gray, R. (1980), An Algorithm for Vector Quantizer Design. IEEE Transaction on Communications, 28 (1), 84–94