
Matthieu Wipliez, Nicolas Siret (Synflow)
Nicola Carta, Francesca Palumbo, Luigi Raffo (EOLAB - University of Cagliari)
Abstract:
Raising the level of abstraction from gate-level descriptions to behavioral descriptions has increased the productivity of hardware designers. High-Level Synthesis (HLS) aims to further reduce design time by transforming C-based descriptions to RTL designs. In this paper, we introduce a new high-level, dataflow programming language called C~ (“C flowâ€) that further increases productivity by raising the level of abstraction from behavioral descriptions, while overcoming the limitations of C for hardware design. We present the syntax and semantics of this language, and the framework that provides hardware and software code generation. This paper illustrates the benefits of using C~ for hardware design of a IEEE 802.3 MAC, synthesized for FPGA and for 90nm CMOS technology.
Index Terms:
hardware design, code generation, dataflow programming, high-level synthesis
I. INTRODUCTION
For the last fifty years, the number of transistors available on a die has been consistently following Moore’s law, doubling every two years. Meanwhile, hardware designers moved from gate-level descriptions to behavioral descriptions of their designs, about twenty years ago. Since that time, the level of abstraction of hardware designs has not changed much, even though today’s chips contain about a thousand times more transistors than they did at the time. The problem is that the design and verification of hardware is increasingly complex and time-consuming at the Register-Transfer Level (RTL).
The most popular alternative to RTL design is High-Level Synthesis (HLS) of C/C++/SystemC programs that many EDA vendors provide. There have been many other attempts at improving hardware design to raise the level of abstraction and reduce design time. The main directions are: improve existing HDLs, provide frameworks for the description of hardware with high-level languages (SystemC, MyHDL...), create new HDLs (Bluespec SystemVerilog [1], C-like HDLs [2]), and use models based on concurrent processes to describe hardware [3, 4].
Despite these numerous efforts, to the best of our knowledge no clearly winning solution has emerged yet, and HDLs are still massively used for hardware design; we give a few reasons that may explain this in section VI when we examine related work. Yet we believe that it is possible to devise a language that could appeal to most hardware and software engineers, and provide a suitable replacement of HDLs, while not being necessarily tied to the development of hardware components. We show such a language in this paper.
This paper makes the following contributions:
- It presents a new high-level programming language called C~ (“C flowâ€) that can be used to design hardware faster than with existing behavioral descriptions written with HDLs. We present the semantics of the language, along with an overview of its syntax, in section III.
- It details hardware code generation from a C~ program to RTL in section IV. We examine previous work and propose a new solution for a more efficient hardware implementation of dataflow programs. We generate technology-independent, well-structured, synthesizable RTL code.
Section II presents the dataflow model of computation, which defines the semantics on which the C~ language is based, and an Intermediate Representation (IR) from the state-of-the-art that we use for transformation of C~ programs to synthesizable hardware and software. Section V presents results obtained with C~ to design an IEEE 802.3 MAC, and synthesize it for FPGA and 90nm CMOS technology. We examine related work in section VI before concluding this article.
II. BACKGROUND
A. Dataflow Model of Computation
A C~ program behaves according to the Dataflow Process Network (DPN) model of computation described by Lee and Parks [5]. This model is a special case of Kahn Process Networks (KPN) [6], which is traditionally used as a model for threaded programs. A program behaving according to the KPN model is composed of a set of concurrent processes that send each other atomic data objects called tokens via unbounded unidirectional FIFOs through ports. Each process is composed of a sequence of reads, computations, and writes freely interleaved. Conversely, in the DPN model, a process is called an actor and is composed of a sequence of firing rules defined below.
A firing rule defines a non-preemptive (uninterruptible) quantum of computation as (1) the number of tokens that are consumed and produced, (2) a predicate that returns true if the rule can be satisfied, and (3) a function that produces output tokens from input tokens. A program that respects the DPN model executes by executing all its actors repeatedly. Each time an actor is executed, the first firing rule that can be satisfied is executed. An actor can have a Finite State Machine (FSM) where each transition is paired with a firing rule. Additionally, a firing rule can change the current state when it is executed.
Process networks have two properties that make them interesting for the description of hardware designs and multiprocessing software. They provide explicit concurrency, and also prohibit side-effects, in other words a process cannot modify the state variables of another process, as this would make the model non-deterministic [6]. The literature contains many articles on hardware synthesis and software code generation from both KPN (e.g. [3], [7]–[9]) and DPN models (for instance see [10]–[13]). We use DPN rather than KPN because an actor can be mapped to hardware in a straightforward and predictable manner by executing each firing rule in a clock cycle [11]. It is also possible to analyze the behavior of DPN actors at compile-time [14], [15], which is useful to prevent deadlocks, or to reduce memory consumption [16].
B. Intermediate Representation (IR) of DPN Actors
Hardware and software code generation of a C~ program leverage on the benefits provided by an Intermediate Representation (IR) that was originally designed as an IR of the CAL language [4]. This IR is described in [17] and is being used in an open-source compiler for dataflow programs called Orcc . The IR of an actor is defined according to the DPN model. It has input and output ports, firing rules, and a Finite State Machine (FSM). A firing rule has patterns, which associate an input/output port with a number of tokens read/written by the firing rule. It also has two procedures (which can be in SSA form [18]), one that defines the predicate associated with the rule, and a second one that defines the behavior of the rule.
This IR was designed specifically for dataflow, with analysis and source code generation in mind, so that it is easier to analyze and transform than source code or lower-level IRs (such as LLVM [19]), for instance it has arbitrarily complex expressions rather than three-address code, and expresses code in a structured way (with “if†and “while†blocks) rather than as a control-flow graph (with blocks and conditioned jumps). This allows the generation of higher-level and more readable source code, being C [12], VHDL [11], or other languages (see the Orcc project for additional code generators).
III. DESCRIPTION OF THE C~ LANGUAGE
As presented in the previous section, a Dataflow Process Network is composed of a set of concurrent processes connected together via FIFO channels. The C~ language allows the definition of tasks, which are a subset of DPN actors. This section describes the structure of a C~ program, an example of the language’s syntax, and then presents its semantics.
A. Structure of a C~ program
A C~ program is organized as a set of files, that can be either headers or tasks. A header is similar to a VHDL package or an include file in C or Verilog, and contains definitions of types, constants and stateless functions. A task is similar to a VHDL entity, Verilog module, or C implementation unit, it declares input/output ports, and must define a “main†function. A task can define type aliases (with typedef), state variables (possibly with an initial value that is a compile-time constant), computational functions, that return a result computed from parameters and state variables and may not modify state variables nor read/write ports, and void functions, with no parameters that can only be called from other void functions (including the “main†function). Finally, a task may have an “init†void function that is only executed once when the task is initialized.
All these elements are internal to the task and cannot be accessed from other tasks or headers. This enforces the properties of the DPN model by allowing tasks to communicate only through ports.
B. Syntax of C~
The syntax of the C~ language is a subset of C99’s syntax [20], with addition of constructs to support dataflow semantics. Figure 1 shows the C~ source code of a simple Run-Length Encoder (RLE), limited to a 32K window. When the code is initialized, the “init†function executes once: it reads one byte and assigns it to “d_refâ€. When the code runs, it simply executes the “main†function forever. This function reads one byte from “data†every cycle, and when it differs from “d_ref†(or it is equal to the 32K window limit), it outputs the reference value and the number of repetitions, and start again.

Figure 1. A C~ implementation of RLE.
C. Semantics
A C~ task is defined as a sequential process and behaves according to the DPN model, i.e. it is modeled as a sequence of firing rules. When a C~ program is transformed to hardware, a firing rule is equivalent to a cycle. Conversely, such a relation is irrelevant when targeting software: what matters is that a task as a whole should minimize its Communication to Computation Ratio (CCR) to maximize its performance (see [21] for a detailed study). Since the language can target hardware or software, it should be able to allow both use cases. This requirement, as well as fifty years of programming, suggests that a sequential process is more appropriate than a list of firing rules for the description of a task.
In this section we focus on the semantics of the C~ language in terms of hardware. The first rule defines the consumption of tokens: in a cycle, data can be consumed from a given input port at most once, and it may be peeked (or tested) any number of times; we detail this with the semantics of conditional and loop statements. The second rule of the language defines the production of tokens: in a cycle, an output port can be written to at most once. The third rule is that an expression or a statement is executed in the current cycle, unless one of these rules cannot be verified, in which case execution continues in a new cycle.

Figure 2. Illustration of the rules of C~.
Figure 2 shows an example of how these three rules applies on a simple C~ task. The main function always starts a new cycle. The assignment to “d†is executed in the current cycle (rule 1). The first “write†is executed in the current cycle (rule 2 and 3). The second “write†must be executed in a new cycle to satisfy rule 2. The corresponding FSM is shown on Fig. 3.

Figure 3. FSM of the code shown on Fig. 2.
Conditional and loop statements may be executed in the current cycle provided that they do not contain reads or writes: this kind of conditional or loop is purely computational. Otherwise, they become multi-cycle statements associated with additional states and transitions following the patterns shown on Fig. 4. For instance, the “if†statement of Fig. 1 is transformed to two transitions (one per conditioned branch), because it contains reads and writes.
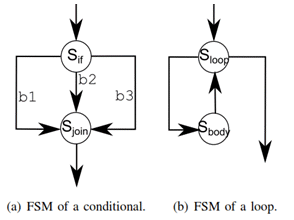
Figure 4. FSM of conditional and loop statements.
Finally, read expressions that appear in the condition(s) of a multi-cycle conditional (such as the “if†of Fig. 1) or loop statement have specific semantics. The read calls that appear in these conditions peek at the token present on the port without consuming it. The token is consumed only by the branch whose condition is true, either by an explicit call to read in the same cycle (as in the “else†branch of the example), or implicitly (as in the “then†branch of the example).
IV. CODE GENERATION FROM C~ PROGRAMS
Hardware code generation or hardware synthesis of dataflow programs is not new. The work we present in this section is based on our previous work [11], which proposed an alternative to the existing approach of hardware synthesis of dataflow programs pioneered by Janneck et al. detailed in [10].
A. Implementation of FIFOs
We limit ourselves to the set of DPN programs that do not require infinite FIFOs to execute correctly. With the exception of artificial programs used to study properties of the model, this set covers all practical programs. DPN allows firing rules with an arbitrary number of tokens on input ports, which requires specific transformations and internal buffers for execution on hardware [22], which translates to an important overhead in terms of area. Fortunately, C~ limits the production/consumption to at most one token per port per cycle, so we do not need to handle this particular case. In practice the sequential coding style inside a C~ task mostly removes the need for reading/writing several tokens on a given port.
The challenge in implementing FIFOs of a DPN model is to minimize communication overhead. Previous work generated asynchronous handshake-style interfaces connected with FIFOs (whose default length is one) [10], [11]. This has the advantage that different actors need not have the same execution rate, and that data is never lost because an actor is only executed if the FIFOs connected to its output ports are not full.
We are taking a different approach from previous work: the generated hardware has no handshake signals, and no FIFOs. In the case of actors with different execution rates, this is only a problem if an actor produces more data than the actor it is connected to can consume, as it will overwrite unconsumed data. To detect that, we use a cycle-accurate, instrumented, software simulation (based on our previous work [17]), that detects overwrites.
B. Translation of Tasks
A network of tasks becomes a module that instantiates and connects the tasks together. Unless FIFOs are explicitly instantiated by the designer, this results in a strict one-to-one mapping between the DPN model and the generated hardware design. Each task is translated from the IR of a C~ task to RTL with two processes (or always blocks) and a FSM. The first process is an asynchronous RTL representation generated from the IR of each firing rule’s predicate that computes which firing rule can be executed. The second process is synchronous, and implements the behavior of each firing rule, executing at most one firing rule per clock cycle, reading data, performing operations, and writing data. The FSM is a one-to-one mapping of the FSM defined in the IR.
The generated hardware has the same cycle-accurate behavior as the original C~ code, i.e. the code is not altered with pipelining or retiming. The RTL code is well structured, as opposed to the gate-level code often produced by HLS tools, and it respects a synthesis-friendly coding style. This allows code generated from C~ to be shipped as IP without dependencies to a particular library, and to be synthesized for any FPGA type, as well as for ASIC, as we demonstrate below.
V. RESULTS
We are writing a standard-compliant C~ implementation of the IEEE 802.3 Media Access Control (MAC) layer for Fast Ethernet (100 Mb/s) and Gigabit Ethernet (1 Gb/s). We detail in this section our implementation and synthesis results for the PHY configuration and MAC encapsulation.
A. Design
The top network instantiates the PHY configuration and MAC encapsulation components (Figure 5). The MAC encapsulation converts a stream of bytes to Ethernet frames, by adding the preamble pattern and Start Frame Delimiter before the frame, and the CRC computed on-the-fly at the end of the frame. The encapsulation handles both 100 Mb/s and 1 Gb/s speeds (with clocks respectively of 25 MHz and 125 MHz, and data width of 4 bits and 8 bits per cycle respectively). The speed is auto-negotiated and returned by the PHY configuration layer described below.

Figure 5. Network for PHY configuration and send MAC frames.
Figure 6 shows the “phyTop†network, which implements configuration of an external component (called PHY by the 802.3 standard) via a standard interface called MII (Media Independent Interface) or GMII (Gigabit MII) in the case of Gigabit Ethernet. The MII defines a simple frame-based protocol that uses a single wire called MDIO (Management Data Input/Output). In our design, the “phyMIIMI†component implements the MII Management Interface in only 80 lines of C~ code, based on three signals MDI, MDO and MDO_EN that are translated from/to the MDIO input/output signal with a tristate.

Figure 6. PHY configuration and MII Management Interface.
B. Implementation
We implemented this design for a Lattice ECP3 FPGA, on the Lattice Versa Development Kit board. For the PHY configuration and MAC encapsulation, this translates to 640 LUTs and 335 registers, implemented with 381 slices, which is about two percent of the whole FPGA. The design, with no optimization whatsoever, can run at a maximum frequency of 171.8 MHz, which is more than enough: Gigabit Ethernet only requires a design that runs at 125 MHz. We have uploaded the bitstream and verified that the generated hardware from the original C~ program works flawlessly.
The design can also be synthesized for other FPGA vendors, for instance on a Xilinx Spartan6 this gives 627 Slice LUTs, 293 Slice Registers, for a maximum frequency of 155 MHz, so again greater than the required frequency.

Figure 7. Respective area for different networks.
An ASIC synthesis trial has been performed adopting a 90nm CMOS technology and exploiting SoC Encounter, a dedicated synthesis tool in the commercial release of Cadence. The maximum achievable operating frequency is approximately 833 MHz, corresponding to an area of 12321 µm² and a total power consumption of 4,3 mW. For the target frequency of 125 MHz, the area is 9480 µm² with a corresponding power consumption of 0.9 mW. Figure 7 presents the distribution of the area among the different networks.
VI. RELATED WORK
As we said in the introduction of this paper, HLS of C/C++/SystemC is the most popular alternative to RTL design, with the following products being the most popular: C-to-Silicon Compiler (Cadence), Catapult-C (Calypto), Cynthesizer (Forte Design Systems), CoDeveloper (Impulse Accelerated Technologies), Synphony C Compiler (Synopsys), Vivado (Xilinx). There also are a few open-source tools that feature HLS of C/C++/SystemC programs, including C-to-Verilog, GAUT, LegUp, or ROCCC.
HLS reduces design time compared to traditional HDLs by raising the level of abstraction, but the C language [20] has many features that make no sense for hardware descriptions or cannot be transformed to synthesizable hardware (such as sequence points, memory allocation, arbitrary pointers, system calls), while lacking features that are useful or necessary for hardware descriptions (e.g. specification of interfaces, bit-accurate type system, bit selection and concatenation, description of cycle accurate behavior).
A different type of approach is the use of a specific language whose semantics are either closer to hardware or even dedicated to hardware. Examples include CAL [4], Bluespec SystemVerilog (BSV) [1], or SHIM [23]. BSV is based on the notion of atomic transactions whose semantics is close to firings. SHIM uses a model of computation based on Kahn Process Networks (KPNs) with rendez-vous communications.
By reusing the same IR as the Open RVC-CAL Compiler, a C~ program can be interpreted, analyzed, and transformed with the same approaches that make use of the CAL and RVC-CAL [24] languages. For instance, this could allow C~ programs to minimize the area of hardware when implementing a multi-decoder design [25]. Analysis of C~ code to determine its behavior at compile-time is possible with approaches such as [14-15], [26]. Existing work has shown that hardware/software co-design from DPN can be interesting [27], [28], and could be reused with C~ code.
VII. CONCLUSION
We introduced in this paper the C~ language, which is a new high-level programming language that can be used for hardware design. We gave an overview of its syntax, a subset of C with the addition of dataflow-specific constructs, and its semantics, which is based on the DPN model. We described hardware code generation from a C~ program by extending previous work on hardware code generation from dataflow programs, and we presented the results we obtained on a part of an IEEE 802.3 MAC implementation. Results showed that a C~ program can be transformed to an efficient RTL design, with the advantage of being higher-level, more concise, and faster to design than a behavioral description.
We have several directions for future work. First, we have started to write a precise specification of C~, so that designers can reliably work with the language, and to prepare a possible future standardization. We are also examining more use cases to make sure the language allows all kinds of hardware designs, and we will add new constructs if necessary. Another direction for future work is to derive efficient mixed hardware/software implementations from C~ designs.
References:
[1] R. Nikhil, “Bluespec System Verilog: efficient, correct RTL from high level specifications,†in Formal Methods and Models for Co-Design, 2004. MEMOCODE’04. Proceedings. Second ACM and IEEE International Conference on. IEEE, 2004, pp. 69–70.
[2] S. Edwards, “The challenges of hardware synthesis from C-like languages,†in Design, Automation and Test in Europe, 2005. Proceedings. IEEE, 2005, pp. 66–67.
[3] T. Stefanov, C. Zissulescu, A. Turjan, B. Kienhuis, and E. Deprette, “System design using Khan process networks: the Compaan/Laura approach,†in Design, Automation and Test in Europe Conference and Exhibition, 2004. Proceedings, vol. 1. IEEE, 2004, pp. 340–34.
[4] J. Eker and J. Janneck, “CAL language report,†University of California at Berkeley, Tech. Rep. UCB/ERL M, vol. 3, 2003.
[5] E. Lee and T. Parks, “Dataflow process networks,†Proceedings of the IEEE, vol. 83, no. 5, pp. 773–801, 1995.
[6] G. Kahn, D. MacQueen et al., Coroutines and networks of parallel processes, 1976.
[7] I. Augé, F. Pétrot, F. Donnet, and P. Gomez, “Platform-based design from parallel C specifications,†Computer-Aided Design of Integrated Circuits and Systems, IEEE Transactions on, vol. 24, no. 12, pp. 1811– 1826, 2005.
[8] W. Haid, L. Schor, K. Huang, I. Bacivarov, and L. Thiele, “Efficient execution of Kahn process networks on multi-processor systems using protothreads and windowed FIFOs,†in Embedded Systems for Real-Time Multimedia, 2009. ESTIMedia 2009. IEEE/ACM/IFIP 7th Workshop on. Ieee, 2009, pp. 35–44.
[9] C. Miranda, A. Pop, P. Dumont, A. Cohen, and M. Duranton, “Erbium: A deterministic, concurrent intermediate representation to map data-flow tasks to scalable, persistent streaming processes,†in Proceedings of the 2010 international conference on Compilers, architectures and synthesis for embedded systems. ACM, 2010, pp. 11–20.
[10] J. Janneck, I. Miller, D. Parlour, G. Roquier, M. Wipliez, and M. Raulet, “Synthesizing hardware from dataflow programs: An MPEG-4 simple profile decoder case study,†in Signal Processing Systems, 2008. SiPS 2008. IEEE Workshop on. IEEE, 2008, pp. 287–292.
[11] N. Siret, M. Wipliez, J. Nezan, and A. Rhatay, “Hardware code generation from dataflow programs,†in Design and Architectures for Signal and Image Processing (DASIP), 2010 Conference on. IEEE, 2010, pp.113–120.
[12] M. Wipliez, G. Roquier, and J. Nezan, “Software code generation for the RVC-CAL language,†Journal of Signal Processing Systems, vol. 63, no. 2, pp. 203–213, 2011.
[13] H. Yviquel, E. Casseau, M. Wipliez, and M. Raulet, “Efficient multicore scheduling of dataflow process etworks,†in Signal Processing Systems (SiPS), 2011 IEEE Workshop on. IEEE, 2011, pp. 198–203.
[14] M. Wipliez and M. Raulet, “Classification of Dataflow Actors with Satisfiability and Abstract Interpretation,†International Journal of Embedded and Real-Time Communication Systems (IJERTCS), vol. 3, no. 1, pp. 49–69, 2012.
[15] J. Ersfolk, G. Roquier, J. Lilius, and M. Mattavelli, “Scheduling of dynamic dataflow programs based on state space analysis,†in Proc. 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2011, pp. 1661–1664
[16] K. Desnos, M. Pelcat, J. Nezan, S. Aridhi et al., “Memory Bounds for the Distributed Execution of a Hierarchical Synchronous Data-Flow Graph,†in Proceedings 2012 International Conference on Embedded Computer Systems: Architectures, Modeling and Simulation, 2012.
[17] M. Wipliez, “Compilation infrastructure for dataflow programs,†Ph.D. dissertation, INSA of Rennes, 2010.
[18] R. Cytron, J. Ferrante, B. Rosen, M. Wegman, and F. Zadeck, “Efficiently computing static single assignment form and the control dependence graph,†ACM Transactions on Programming Languages and Systems (TOPLAS), vol. 13, no. 4, pp. 451–490, 1991.
[19] C. Lattner and V. Adve, “LLVM: A compilation framework for lifelong program analysis & transformation,†in Code Generation and Optimization, 2004. CGO 2004. International Symposium on. IEEE, 2004, pp. 75–86. ISO, C Language, 1999.
[20] ISO, C Language, 1999.
[21] M. Pelcat, S. Aridhi, J. Piat, and J.-F. Nezan, Physical Layer Multi-Core Prototyping: A Dataflow-Based Approach for LTE eNodeB, 2013th ed. Springer, Aug. 2012.
[22] K. Jerbi, M. Raulet, O. Deforges, and M. Abid, “Automatic Generation of Synthesizable Hardware Implementation from High Level RVC-CAL Description,†in Acoustics, Speech and Signal Processing (ICASSP), 2012 IEEE International Conference on. IEEE, 2012, pp. 1597–1600.
[23] S. Edwards and O. Tardieu, “SHIM: A deterministic model for heterogeneous embedded systems,†Very Large Scale Integration (VLSI) Systems, IEEE Transactions on, vol. 14, no. 8, pp. 854–867, 2006.
[24] ISO/IEC, ISO/IEC 23001-4:2011 Codec configuration representation.
[25] F. Palumbo, D. Pani, E. Manca, L. Raffo, M. Mattavelli, and G. Roquier, “RVC: A multi-decoder CAL Composer tool,†in Design and Architecturesfor Signal and Image Processing (DASIP), 2010 Conference on. IEEE, 2010, pp. 144–151.
[26] J. Boutellier, C. Lucarz, S. Lafond, V. Gomez, and M. Mattavelli, “Quasi-static scheduling of CAL actor networks for reconfigurable video coding,†Journal of Signal Processing Systems, vol. 63, no. 2, pp. 191–202, 2011.
[27] G. Roquier, C. Lucarz, M. Mattavelli, M. Wipliez, M. Raulet, J. Janneck, I. Miller, and D. Parlour, “An integrated environment for hw/sw codesign based on a cal specification and hw/sw code generators,†in Circuits and Systems, 2009. ISCAS 2009. IEEE International Symposium on. IEEE, 2009, pp. 799–799.
[28] N. Siret, I. Sabry, J. Nezan, and M. Raulet, “A codesign synthesis from an mpeg-4 decoder dataflow description,†in Circuits and Systems (ISCAS), Proceedings of 2010 IEEE International Symposium on. IEEE, 2010, pp. 1995–1998.