
By Samir Bhatt, Bhaskar Trivedi, Ankur Devani, Hemang Bhimani (eInfochips)
Introduction:
In current traffic management systems, there is a high probability that the driver may miss some of the traffic signs on the road because of overcrowding due to neighbouring vehicles. With the continuous growth of vehicle numbers in urban agglomerations around the world, this problem is only expected to grow worse.
A visual-based traffic sign recognition system can be implemented on the automobile with an aim of detecting and recognizing all emerging traffic signs. The same would be displayed to the driver with alarm-triggering features if the driver refuses to follow the traffic signs.
At eInfochips, we have made an attempt to help automotive companies detect and recognize traffic signs in video sequences recorded by on-board vehicle camera. Traffic Sign Recognition (TSR) is used to display the speed limit signs. Here, OpenCV is used for image processing. OpenCV is an Open source Computer Vision library designed for computational efficiency with a strong focus on real time applications.
We have classified the flow according to two phases : Detection and Recognition
- Detection
- Blurring
- Colour-based detection
- Shape-based detection
- Cropped and Extract features
- Separation
- Recognition
- Tesseract
- SVM
Block Diagram:

Detection
Traffic signs in India are bound by red colour circles. So, the focus is really on red-circled objects in a given frame or image. The detection process includes the following steps:
• Blurring: Raw image may include random or AWGN noise like black dots due to a less efficient capturing device. Also, due to improper illumination, some part of this image may have sharp edges or abrupt colour changes which can affect the entire detection process. So, to reduce noise or to smoothen the image, we need to have a blur-like effect. There are two types of blurring which are used.
- medianBlur() : it reduces salt and paper noise
- GaussianBlur() : This can be applied on sharpened edges for smoothing
There are two approaches to detecting the object,
• Colour-based Detection: Colour is one of the most powerful attributes for object detection. By default, colour image information is represented in Cartesian colour space which happens to be RGB (Red, Green, and Blue). RGB is an additive colour system based on tri-chromatic theory. There are different colour spaces available like HSV or HSL, CMY (K), YIQ etc. HSV (Hue, Saturation, and Value) colour space plays an important role in image processing.
-> Changing colour space: Changing colour space from RGB to HSV. HSV represent the colour information in the form of cylindrical co-ordinate systems.
i.e. (rho, phi, and z) -> (Saturation, Hue, and Value).
-> Defined colour ranges: HSV colour space will help to define a particular colour range for object detection. i.e.. red colour. It requires two boundaries: Upper and lower. Combine both the lower and upper boundary images into a single image with appropriate weight. The final image contains only the in range red colour object information.
-> Colour-based detection gives all the red object information present in an image which may or may not interest us. For this reason, we need to classify an image based on shape for accurate detection.
• Shape-based detection: Using shape-based detection, it is possible to detect a particular shape information. i.e.. Circular Objects.
-> In OpenCV, HoughCircle () has the ability to detect specific circular objects in a given gravy scale image. It gives t total number of detected circles with three important parameters. i.e. centre co-ordinates (x, y) and radius.
At this stage, we have detected the information on red circles.
• Cropped and Extract features: Using Rect and mask extract features from red circle.
• Separation: Contour method is used to separate the digits. i.e. “50” -> '5' , '0'
Now that the separated digits pass to a recognition stage. [See Detection_flow.png]
Recognition
There are so many recognition techniques like Tesseract OCR, SVM, Template matching, SIFT, SURF, ORB, HOG, MSER etc
1. Tesseract
Tesseract OCR (Optical Character Recognition) is best for character recognition. Moreover, it provides open source OCR engine. Tesseract has its own predefined libraries. It has its own set of trained data for character recognition as well as with the help of Leptonica. It supports multiple languages. In this method, by passing text image to the tesseract, API recognizes a givn character in the form of text. Tesseract is a command line utility which will generate recognized text from the input image with the help of training data set available in the system. Tesseract also provides C++ API which can be implemented in any program.
2. SVM
Support Vector Machine is a part of Machine Learning concept. SVM has the ability to classify and recognize images with the help of trained data.
How SVM works?
A Support Vector Machine (SVM) is a discriminative classifier formally defined by a separating hyperplane. In other words, given a labelled training data (supervised learning); the algorithm outputs an optimal hyperplane which categorizes new examples.
For a linearly separable set of 2D-points which belong to one of two classes, it helps in finding a separating straight line. [See separating-lines.png]
The operation of the SVM algorithm is based on finding the hyperplane that gives the largest minimum distance to the training examples. More than twice, this distance receives the important name of margin within SVM’s theory. Therefore, the optimal separating hyperplane maximizes the margin of the training data. [See optimal-hyperplane.png]
How is the optimal hyperplane computed?
Notation used to define formally a hyperplane:
f(x) = B0 + BTx
Where B is known as a weight vector and B0 as the bias.
The optimal hyperplane can be represented as,
| B0 + BTx | = 1
Where x symbolizes the training examples closest to the hyperplane. In general, the training examples that are closest to the hyperplane are called support vectors.
The distance between a point x and a hyperplane ( B, B0) :
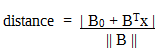
In particular, for the canonical hyperplane, the numerator is equal to one and the distance to the support vectors is
![]()
The margin M is the twice the distance of the closest examples:
![]()
Finally, the problem of maximizing M is equivalent to the problem of minimizing a function L(B) subject to some constraints. The constraints model the requirement for the hyperplane to classify correctly all the training examples
![]()
Where yi represents each one of the labels of the training examples.
The steps to recognizing an image using SVM includes:
1) Setting up the Training data:
To train a set of images on SVM, we first have to construct the training matrix for the SVM. This matrix is specified as follows: each row of the matrix corresponds to one image, and each element in that row corresponds to one feature of the class. In this case, the colour and the support vector of the pixel at a certain point. Since images are 2D, we need to convert them to a 1D matrix. The length of each row will be the area of the image and we need to assign a label for each trained images. (Note that the images must be the same size). [See SVM_Training.png]
int label[10] = {0,1,2,3,4,5,6,7,8,9};
Mat trainingDataMat(10,3500,CV_32FC1);
Here 10 images of 50x70 each, converted into 1-D matrix of 1x3500 sizes. Also set label for each 1-D matrix.
2) Set up SVM’s parameters
Ex:
Ptr<SVM> svm = SVM::create();
svm->setType(SVM::C_SVC);
svm->setKernel(SVM::LINEAR);
svm->setTermCriteria(TermCriteria(TermCriteria::MAX_ITER, 100, 1e-6));
Type of SVM : C_SVC that can be used for n-class classification (n >=2).
Type of SVM kernel : LINEAR means mapping done to the training data to improve its resemblance to a linearly separable set of data
Termination criteria of the algorithm : It specify a maximum number of iterations and a tolerance error.
3) Train the SVM
Ex:
svm->train(trainingDataMat, ROW_SAMPLE, labelsMat);
svm->save("svm_training.xml");
It is a method to build svm model in the form of training. It specifies that each trained image sample contains in row samples and store training information in .xml file.
4) Test images using trained SVM data
Ex:
float response = svm->predict(sampleImage);
Simply read an image, convert it to a 1D matrix, and pass that in to svm->predict();
It will return label of the matched trained image.
3. Template matching :
Template matching is a technique in digital image processing for finding small parts of an image which match a template image. It can be used in manufacturing as a part of quality control, object recognition, a way to navigate a mobile robot, or as a way to detect edges in images.
To identify the matching area, we have to compare the template image against the source image by sliding template image over source image.
By sliding, we can move the patch one pixel (centre pixel of template image) at a time (left to right, up to down), at each location. It will gives the result in form of a matrix which represents how “good” or “bad” the match at that location is (or how similar the patch is to that particular area of the source image).
For each location of T (template image) over I (source image), we can store the result in result matrix (R). Each location (x,y) in R (result matrix) contains the matching result. The brightest location indicates the highest matches.
In this case of template matching, first convert each details and templates into fixed size resolution, and perform pixel by pixel arithmetic operation. So sliding is performed only once in this process. According to defined arithmetic operation and its matching value with template image we can recognise image.
Template matching offers six different calculation methods:
method 1 :: CV_TM_SQDIFF: squared difference
R(x,y)=sumx',y'[T(x',y')-I(x+x',y+y')]2
method 2 :: CV_TM_SQDIFF_NORMED: normalized squared difference
R(x,y)=sumx',y'[T(x',y')-I(x+x',y+y')]2/sqrt[sumx',y'T(x',y')2•sumx',y'I(x+x',y+y')2]
method 3 :: CV_TM_CCORR: cross correlation
R(x,y)=sumx',y'[T(x',y')•I(x+x',y+y')]
method 4 :: CV_TM_CCORR_NORMED: normalized cross correlation
R(x,y)=sumx',y'[T(x',y')•I(x+x',y+y')]/sqrt[sumx',y'T(x',y')2•sumx',y'I(x+x',y+y')2]
method 5 :: CV_TM_CCOEFF: correlation coefficient
R(x,y)=sumx',y'[T'(x',y')•I'(x+x',y+y')],
where T'(x',y')=T(x',y') - 1/(w•h)•sumx",y"T(x",y")
I'(x+x',y+y')=I(x+x',y+y') - 1/(w•h)•sumx",y"I(x+x",y+y")
method 6 :: CV_TM_CCOEFF_NORMED: normalized correlation coefficient
R(x,y)=sumx',y'[T'(x',y')•I'(x+x',y+y')]/sqrt[sumx',y'T'(x',y')2•sumx',y'I'(x+x',y+y')2]
where I = Source image , T = Template image.
4. ORB :
When template matching fails in recognition, then control goes by default to ORB for recognition.
The most important thing about ORB is, that it came from “OpenCV Labs”. It is a combination of two algorithms; FAST and BRIEF feature. ORB is a good alternative to SIFT and SURF in terms of computation costs, matching performance and mainly the patents. Yes, SIFT and SURF are patented and you are supposed to pay for the use. But, ORB is not !!!
ORB is basically a fusion of FAST keypoint detector and BRIEF descriptor with many modifications to enhance the performance. First, it use FAST to find keypoints, then applies Harris corner measure to find top N points among them. It also use pyramids to produce multiscale-features. But there is one problem, FAST doesn’t compute the rotation orientation. Authors came up with BRIEF modification.
ORB has a number of optional parameters. Most useful are nFeatures which denote a maximum number of features to be retained (by default 500), scoreType which denotes whether Harris score or FAST score would rank the features (by default, Harris score) etc. Another parameter, WTA_K decides the number of points that produce each element of the oriented BRIEF descriptor. By default, it is two, i.e. selecting two points at a time. In that case, for matching, NORM_HAMMING distance is used. If WTA_K is 3 or 4, which takes 3 or 4 points to produce BRIEF descriptor, then matching distance is defined by NORM_HAMMING2
Recognition Output:

Figure 1: Traffic sign recogntion output, LIVE traffic in Ahmedabad, India (Source: eInfochips)
Observation Table:
| Resolution | Time in ms(Template, orb) | Time in ms(Tesseract, SVM) |
| 360p(480*360) | 24 44 41 33 | 108.93 166.39 169.38 93.33 |
| 480p(858*480) | 32 37 42 32 | 111.84 178.94 111.78 112.76 |
| 720p(1280*720) | 69 | 111.79 |
| 1080p(1920*1080) | 140 338 88 | 133.81 195.35 240.31 177.24 |