
By Arohan Mathur, eInfochips
Abstract
In any design verification project, many times, there is a need to control certain functional threads in parallel. Such threads can be used to control simultaneous stimuluses, to monitor activities on certain interfaces running in parallel, to collect information for complex coverage blocks, etc. A user has to come up with a fine and stable control method for all such parallel functional threads, to achieve the final verification goal using the verification features.
System Verilog LRM (Language Reference Manual) defines “a process” as “A thread of one or more programming statements that can be executed independently of other programming statements.”
Unlike Verilog, there are two types of processes in System Verilog - static processes and dynamic processes.
Static Process: Static process execution begins at the start of the simulation and cannot be created at runtime. Its existence is determined by the static instance hierarchy.
Static processes are in the form of initial procedures, always, always_comb, always_ff procedures.
Dynamic Process: It is a process that can be created, stopped, restarted, and destroyed at runtime.
These processes are in the form of “fork … join, fork …join_none” and “fork … join_any”.
This paper explains the blocks that allow users to have processes running in parallel and different ways to have a fine control over these processes along with relevant simple examples.
Parallel Blocks
A Verilog fork … join statement always blocks the parent process until all the processes inside fork … join block are executed. System Verilog supports parallel processes using the fork … join, fork … join_any, fork … join_none blocks and implements a process class to have a fine control over these processes.
There are three ways in which the parent process may resume execution in System Verilog,
fork … join
fork … join_any
fork … join_none
fork … join
All the processes inside the fork … join block will execute in parallel. The parent process is blocked until all the processes spawned inside fork … join completes their execution.
Let’s take an example where two processes start their execution in parallel. In Process 1, variable count1 is incremented by 1 every 5ns. In process 2, variable count2 is incremented by 1 every 10ns. Both these processes increment the variables count1 and count2 five times respectively.

In the case of fork … join, both the processes spawn in parallel. Both count1 and count2 start incrementing concurrently. Count1 and 2 takes 25ns and 50ns respectively to reach the maximum value and thus at 50ns, both the processes inside fork … join complete their execution and the parent process resumes. Therefore, at 50ns, we see a display from the parent process.

fork … join_any
All the processes inside the fork … join_any block will execute in parallel. The parent process is blocked until any one of the processes spawned inside fork … join_any completes its execution.
By replacing fork … join in the previous example with fork … join_any, it is observed that both the processes start their execution in parallel, but the parent process resumes its execution at 25ns. A counter in process 1 increments the count by 1 every 5ns while the counter 2 does the same every 10ns. Thus, the counter 1 reaches its maximum value before process 2. As soon as process 1 is completed at 25ns, parent process resumes its execution.

fork … join_none
All the processes inside the fork … join_none block will execute in parallel. The parent process is not blocked and will continue execution.
After replacing fork … join with fork … join_none in the previous example, it is observed that both the processes spawn and the counters start incrementing while the parent process continues its execution.
The parent process resumes its execution at 0ns while the processes inside fork … join_none spawns and continue their execution further.

wait fork
wait fork blocks the execution of the calling process until all its immediate child processes are completed.
Output of the fork … join_any without wait fork:

fork … join_any with wait fork:
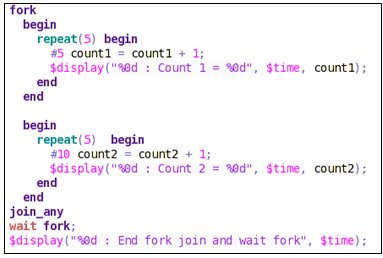
In fork … join_any, the parent process waits for any one of the processes inside fork … join_any to complete its execution before resuming its own execution. If wait fork is specified, the parent process will wait for all the processes inside the fork … join_any block to complete. Thus, in this case, the parent process resumes its execution at 50ns, unlike the case without wait fork where the parent process resumes execution at 25ns after the completion of process 1.
disable fork
The disable fork statement terminates all the sub-processes of the calling process.
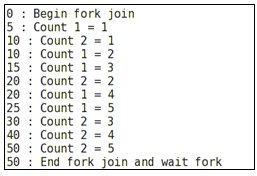
Output of the fork…join_any without disable fork:

fork … join_any with disable fork:
In fork … join_any, the parent process waits for any one of the processes inside fork … join_any to complete its execution before resuming its own execution. Though the parent process resumes its execution, the remaining processes inside fork join continue along with the parent process. If a disable fork is specified outside the fork … join_any block, the remaining processes inside it are terminated / killed. Thus, in the example above, the process 2 was terminated after the completion of process 1 at 25ns.
Parallel Process Control
System Verilog defines a built-in class “Process” that provides users with fine control over the processes. It allows users to define variables of type process and pass them through tasks.
The methods provided in process class to let users control the processes are,
- self ();
- kill ();
- await ();
- suspend ();
- resume ();
- status ();
self ()
static function process self ();
This function returns the handle to the current process i.e. the handle to the process that is making the call.

This handle is used to perform all the process control operations.
kill ()
The kill () function terminates the process and all its sub-processes. If the process is not blocked (due to wait statement, delay or waiting for an event to trigger), then it will be terminated in the current timestamp.
Let’s take an example of a counter that increments the count by 1 every 5ns and counts up to count = 5. Given below is the output of the normal execution:
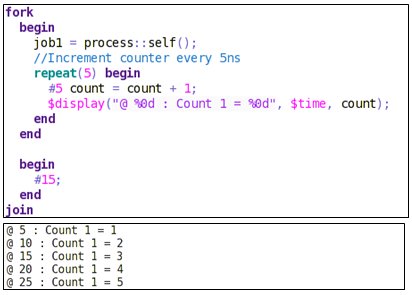
Now, suppose the process is killed using kill () after 15ns.

The counter will stop counting after 15ns thus, the value of the counter will increment just twice.
![]()
await ()
This task allows one process to wait for another process.
Note: Calling this task in the current process will result into an error.
There are two counters running in parallel. Both these counters will increment their counts until the count = 3.
Output of fork … join without await ():

fork … join with await ():
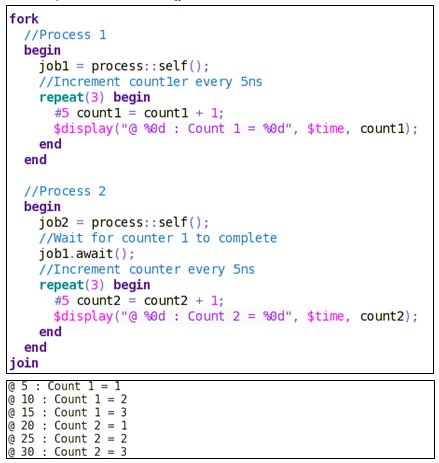
await () makes Process 2 wait for process 1 to complete.
Therefore, counter 2 will wait for counter 1 that will keep incrementing until its count = 3 and thereafter counter 2 will proceed.
suspend ()
This function suspends the execution of the process. It can suspend its own or other process’s execution. The execution is suspended until a resume () is encountered. If the process is not blocked (due to wait statement, delay or waiting for an event to trigger), then it will be suspended in the current timestamp.
resume ()
This function restarts the process that was suspended. Resuming a process that was suspended while being blocked (due to wait statement, delay or waiting for an event to trigger) shall reinitialize that process to the event expression or wait for the wait condition to be true or for the delay to expire.

The output of the above code is,

In the example above, the execution of process 1 is suspended at 5ns and resumed after a delay of 50ns. Therefore, the counter incremented from count = 1 to count = 2 after 50ns.
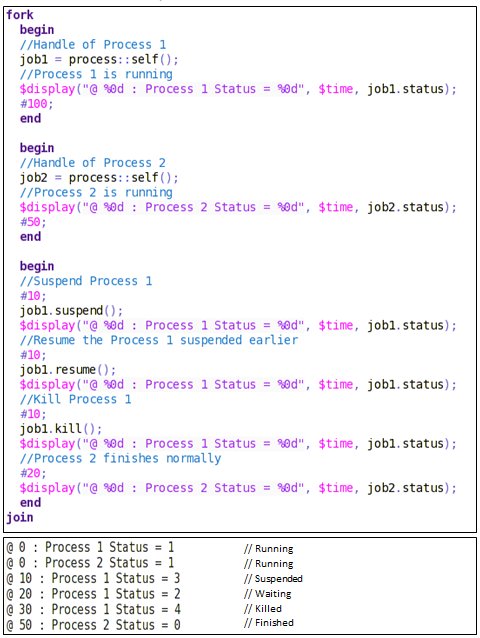
status ()
This function returns the current status of the process.
An enum is defined in the process class,
typedef enum {FINISHED, RUNNING, WAITING, SUSPENDED, KILLED} state
The status is returned as,
0: Finished means the process was terminated normally.
1: Running means the process is currently running.
2: Waiting means the process is in a blocking statement.
The process might be waiting for an event to trigger, a #delay or a wait statement.
3: Suspended means the process is stopped and is waiting for a resume.
4: Killed means the process was forcibly killed via kill or disable.
Parallel Process Control Using Semaphore
Semaphore is used in a situation where a resource is shared among multiple processes. Semaphore is similar to a bucket of keys. We can have one or more keys.
The process that needs the control of the shared resource will occupy a key indicating that the resource is busy and other processes must wait until it puts the key back.
Semaphore is a built-in class that provides the following methods.
- new () - Create a semaphore with a specified number of keys
- get () - Obtain one or more keys from the bucket
- put () - Return one or more keys into the bucket
- try_get () - Try to obtain one or more keys without blocking
new ()
The new () method is used to create a semaphore with N number of keys. If the number of keys is not mentioned, then by default, a semaphore with 0 key is created.

This will create a semaphore named “sema” with 1 key.
put ()
The put () method is used to return N keys back to the semaphore. If the number of keys is not specified, the default number of keys that will be returned is 1.
![]()
get ()
The get () method is used to procure N number of keys from the semaphore.
If the specified number of keys are available, the method returns and the process that asked for the key continues its execution. If the specified number of keys are not available, the process asking for the keys is blocked until the specified number of keys is available.
If the number of keys is not specified, the default value is 1.
![]()
Let’s take an example where we have a common task to execute the process, but there are two processes that need to call the same task.
In a situation like this where we have a resource shared among multiple processes, semaphore is used.
As there are only two processes and one resource, a semaphore with a single key is created. We may have semaphore with multiple keys depending on the complexity.
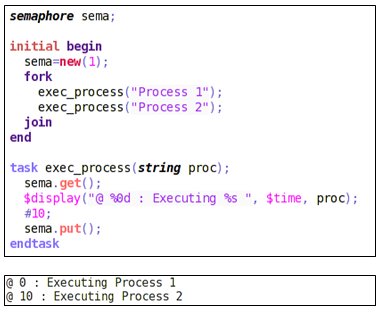
Here, both the processes start their execution in parallel. Process 1 procured the key and thus Process 2 needs to wait for Process 1 to return the key back. Using semaphore, processes take turns to get access to the shared resource.
Output of the above code without using semaphore.
![]()
In the case where semaphore is not used, both the processes start execution in parallel and get access to the task “exec_process” at the same time. This will not work if we have a shared bus, shared memory, controller, etc.
Semaphore with Multiple Keys
A semaphore can have multiple keys. Here is an example where four processes need to call the same task “exec process”. As the number of keys in the semaphore is three, three processes will execute in parallel and the fourth process will start its execution when any of the three processes spawned earlier finishes and releases a key.
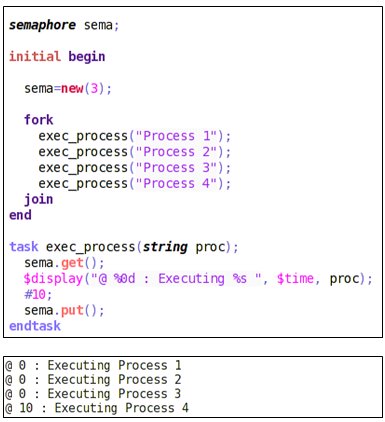
try_get ()
The try_get () method is used to procure N number of keys from semaphore, but without blocking.
If the specified number of keys are available, the method returns a positive integer and the process that asked for the key continues its execution. If the specified number of keys are not available, the method returns 0.
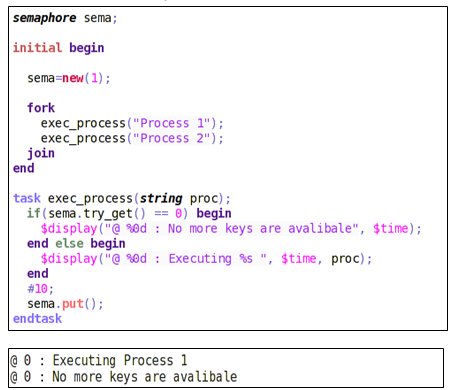
In the case of try_get (), the process will try to procure the key, but unlike get (), if no key is available, the process is not blocked.
Summary
Using the methods in process class and the concept of semaphore explained in this paper, users can have complete control over the processes running in parallel and can have an optimum use of the resources shared between various processes. Based on project-specific needs, users can adopt an approach, which is the best fit for their needs. Using the basic concept, users can implement much complex parallel threads for complex designs under verification.
Author Bio
Arohan Mathur is working as an Engineer at eInfochips, an Arrow company. He has an industry experience of 1.6 years in ASIC Design Verification and has worked on ATE domain verification projects. He has hands-on experience in Functional and SVA-based verification.
About eInfochips:
eInfochips, an Arrow company, is a leading global provider of product engineering and semiconductor design services. With over 500+ products developed and 40M deployments in 140 countries, eInfochips continues to fuel technological innovations in multiple verticals. The company’s service offerings include digital transformation and connected IoT solutions across various cloud platforms, including AWS and Azure.
Along with Arrow’s $27B in revenues, 19,000 employees, and 345 locations serving over 80 countries, eInfochips is primed to accelerate connected products innovation for 150,000+ global clients. eInfochips acts as a catalyst to Arrow’s Sensor-to-Sunset initiative and offers complete edge-to-cloud capabilities for its clients through Arrow Connect.