
by Peter Cumming - Franck Seigneret
TEXAS INSTRUMENTS FRANCE - NICE
Abstract:
The role of interface and socket standards in SoC platforms is explored from the standpoint of wireless handset design in general and Texas Instruments’ OMAP platform in particular. The benefits of a socket approach are described along with some of the characteristics of the ideal socket. The development history of OMAP – a typical SoC platform is described along with our motivations and experiences in adopting a standard socket.
1. Introduction
System on Chip Platforms of one kind or another form the basis of many embedded systems today, and it is widely accepted that their importance will continue to grow over the next few years. The concept of a platform was formalised in [1] and two general categories of platform defined in this paper concern us here: full application platforms and fully programmable platforms. The vast majority of embedded system designs make use of a full application platform which is a standard piece of hardware (one or more chips), typically including a processor and peripherals along with associated low level software and a development environment. Such platforms amortise the spiralling development costs of deep sub-micron ASICs and are therefore, the best choice for the many applications that need near-optimal power, performance or area—this requirement typically preventing the use of significant quantities of programmable logic such as large scale FPGAs.
The second class of platform, the fully programmable platform, referred to here as a SoC platform, is of interest because it provides a mechanism for application platform designers to rapidly develop their products. A SoC platform consists of, at least, a library of reusable hardware modules (components) and an architecture for their interconnection (rules determining legal collections of components in a product as well as a means of performing the interconnection of these components). Such an approach is necessary for many well documented reasons. We focus here on a few factors which we believe are critical in our choice of the SoC platform architecture and specifically, the interface (or socket) standard.
The principle driver is the productivity of the application platform design team and the time to market they can achieve. This drives the systematic reuse of IP modules as SoC platform components, but also mandates that these components are simple to connect together – in practice that they all share a common look and feel – and that the resulting assembly is simple to verify. The verification problem illustrates the key aspect of such an approach: it is essential that each module is fully verified before it is instantiated in the assembly or chip and that only the correctness of its instantiation needs to be verified at the assembly or chip level. This principle, known as decoupling, is also critical in the logical and timing design domain as well as in verification.
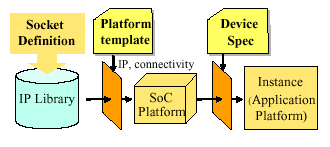
Figure 1: Relationship between sockets, IP and platforms
Closely related to the requirement of application platform designer productivity is the problem of wire. The scaling properties of modern semiconductor processes mean that in the 0.13-0.09um generation designers must carefully budget for long distance connectivity. Hence when assembling a large SoC such as an application platform, it is efficient to think in terms of individual modules with (only) local routing, plugged into one or more discrete interconnect networks at the upper levels of the device hierarchy.
Such an approach is currently essential to give acceptable performance, layout predictability and fast timing convergence. As semiconductor processes continue to scale while the size and complexity of chips also increases, this distinction between block level routing and global interconnect will become ever more critical. As has been suggested in [3], it seems likely that current defensive techniques for top level wiring will run out of steam, SoC interconnects will be viewed as somewhat unreliable, asynchronous networks, and will borrow techniques for reliable, high bandwidth communication from today’s networking world.
The final driver for the use of SoC platforms is compatibility in its many guises. Most obviously, application platform vendors would like to minimise their software investment across the platforms they sell. They would also like to be able to offer a range of software and pin level interface compatible platforms to their customers. This is not always simple since a component can be used in very different environments in different devices: bandwidth requirements, sharing between bus masters, DMA support and other factors can all vary widely. A robust SoC platform will facilitate both software and hardware integration in such cases.
2. Busses, Interfaces and Sockets
As discussed in the previous section, a SoC platform can ease the task of the application platform designer. The architecture of the platform is critical to the SoC platform designer because it profoundly impacts the application platform design and its power, performance, and area.
Firstly, the chosen standard dataflow interface (or interface family) risks greatly impacting the time it takes to complete and verify the initial design, as well as the evolutions that follow (Is the interface well specified - including timing? Does it reduce the chances of finding bugs at chip create? Is it robust against changes in interconnect and other architectural parameters? Can the component be easily migrated into other platforms with alternative interfaces?).
Other aspects of the architecture are equally critical: standard register mappings, effective reservation of control and data path register space for new functions, temporal relations between events on the interfaces as well as interfaces to the system that are not included in the standard interface (event signalling – interrupts and DMA – is the most commonly understood example).
For the designer of a component and for the engineer(s) assembling these components into application platforms or custom chips, it is essential that the SoC platform standardises on many parameters beyond the dataflow interface. Borrowing from the discrete device world, we call this the concept of a socket. For the component and chip create processes to work efficiently, we believe it is essential that a comprehensive socket definition is agreed – this definition encompasses all the non-application specific functionality of a component (i.e., the functionality that is not unique to the component).
We believe that the concept of a socket is critical for the next generations of SoC platforms and is a natural evolution from previous and current practices.
First generation platforms used ad-hoc, bus-based interfaces (in much of Texas Instruments, this was the Rhea, or TIPB, bus mentioned in section 5.2). This approach typically falls short in terms of infrastructure (EDA tools and scripts for timing and functional verification) as well as often being proprietary and hence, hard to use when working with other organisations.
The Virtual Socket Interface Alliance (VSIA, [4]) began its On Chip Bus Development Working Group (OCB DWG) as the concept of interfaces was beginning to emerge. Their Virtual Component Interface (VCI) did much to promote the concept of interface rather than bus-based design. This differentiation is needed to support component exchange and reuse when multiple bus architectures and topologies are used. Such situations arise either due to an installed base of (legacy) components and bus infrastructure or when the interconnect is scaled for performance/power/area such as from a simple shared bus to a partial crossbar. ARM Ltd’s AHB-lite [5] is a good example of an interface standard – in this case, ARM took the established Advanced Microcontroller Bus Architecture and reused the best parts of the two associated busses (ASB and APB) to produce the AHB(-lite) interface. Unfortunately, ARM were not able to maintain backward compatibility with ASB in this process.
In Texas Instrument’s wireless group, we saw the need to adopt an interface such as VCI or AHB-lite, but were determined to expand the scope of our effort to include signals outside the dataflow interface and also to thoroughly specify other aspects that are discussed in section 3. We began working with VCI, but as the momentum behind the OCB DWG faded, we approached Sonics, Inc. who had been a major contributor to VCI and had already been working on the socket concept in their Open Core Protocol (OCP) standard. We soon found that our concerns and objectives were shared by other organisations and so helped Sonics Inc [6] to form the Open Core Protocol International Partnership (OCP-IP) consortium, discussed briefly in section 3 and in [7].
The left hand side of Figure 2 shows how a conventional design, fails to decouple IP modules from the device architecture and interconnection. The right hand side of this figure shows how such a system could be built from socketised modules and a unified interconnect.
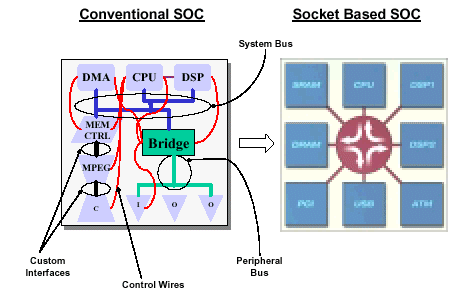
Figure 2: Decoupling through sockets 1 .
3. The ideal socket
Sockets are differentiated from interfaces by their goal of completeness so it is natural to start a description of an ideal socket by enumerating some critical parts of its scope:
3.1 Dataflow
All aspects of the dataflow of a module are the basis of a socket interface, but are also covered by more conventional interfaces such as AHB-lite and hence, will not be dwelt on here.
Several important aspects of dataflow are endianism, address granularity and device width. These areas often form a particular challenge for integrators and are a very common source of errors when less experienced engineers are responsible for related aspects of the design. We have found this to be an important area where very clear guidelines and standards are required.
3.2 Clock cycle
The goal of a socket is to decouple module design from integration and allow module designers to focus on their task without adding the concerns of the chip integrator. The chip integrator is, however, critically concerned by the clocking of the devices he uses:
- The hardware level interfaces must connect with clean clock crossing to avoid risky and latency inducing synchronisation logic.
- The global clocking scheme providing clocks to both interconnect and the various modules must be as simple as possible to minimise power.
- The system level performance, which depends critically on component clock speeds and interface latencies, must be adequate.
- The final chip level timing closure must be achievable and ideally straightforward.
These considerations mean that a true socket, just like its board level equivalent, must include budgets for both clock cycle and interface signal timings.
Of course, in the SoC arena, there are often hierarchies of busses as well as multiple target technologies (from different silicon vendors, but also through technology migrations). The ideal socket therefore, includes requirements on timings for a reference technology, but also includes ‘documentation’ that gives details of actual timings which may be better than those required by the socket definition.
3.3 Clocks
It is clear that large SoCs must be based around a simple and robust clocking methodology and that the socket definition must support this. While SoCs will likely migrate to more complex clocking environments such as locally synchronous, globally asynchronous, the socket should remain simple and synchronous.
This goal is not completely straightforward since many modules in a SoC are required to interface to the external world with specific clock rates, often derived from the interface clock (USB, UART, PCI are a few of the many examples).
Hence, synchronisation logic is generally required between the interconnect and the backend of the module. Two approaches are possible, either the module includes synchronisation logic or an additional level of interface abstraction is added as shown in Figure 3.
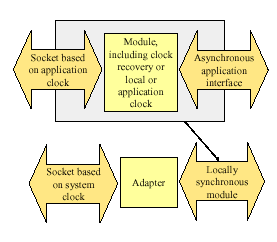
Figure 3: Asynchronous peripheral with clock adapter
The top part of Figure 3 shows a module with an application driven clocking regime on the right hand interface and no synchronisation logic. Hence, the socket interface timings – whether the module is an initiator or target – are relative to the application clock. The lower part of the figure shows an adapter which takes both application and system clocks as inputs and provides a socket synchronous to the system clock.
In this latter approach, the adapter may be subsumed into the interconnect in the form of an agent. This approach is often convenient for the module designer. It is also well suited for integration since in some cases the system clock will be appropriate for the module (for example, a system may be built around a multiple of the PCI clock rate) and the overhead of synchronisation logic is not needed. In other cases, such as links where the clock is derived from the application interface itself, synchronisation may be a natural part of the module design. Hence, we allow both strategies – synchronisation in the module and synchronisation in the interconnect (or a discrete adapter).
3.4 Reset
Since the socket concept is intended to ease SoC integration and module verification, it is critical to include the reset protocol in the definition. Hence, our ideal socket defines the signals used to reset the module and the transitions that occur on them (polarity, duration…) as well as any restrictions on signals driven by the module during and immediately after reset.
3.5 Interrupt and DMA Requests
Signals, protocols (edge or level sensitive) and synchronisation (or absence thereof) in interrupt and DMA signalling must be defined. Where possible, we prefer approaches that support an arbitrary number of these event signals and allow the system integrator to determine whether they are to trigger software (interrupt) or hardware (DMA) responses.
This goal of harmonised event signalling suggests the use of an edge, rather than level, based protocol.
3.6 Semantics
Any CPU based system must deal with the requirements of different types of access:
- Weak order (or memory semantics) allows reordering and merging of accesses provided hazards such as RAW and WAW are avoided. Data can also be forwarded from a write to a following read [8].
- Strong order (or IO semantics) enforces that each access completes to its target before following instructions are executed by the processor [8]. This prevents, for example, writes being posted and the CPU released prior to completion of the write at the target. This type of access is used for IO devices where, for example, reads may change the state of the target (such as reading from a FIFO). A second example is the write that clears an interrupt and is closely followed by interrupts being (re)enabled in the processor: the write must complete to the interrupt controller before the interrupt enable instruction is executed.
- Cache coherence and memory barriers are supported by high performance processors [8]. These advanced features are typically absent from current SoCs, but are likely to become more important in the future. Fortunately, they concern only a few types of module and can hence be added as needed without requiring a change to the majority of legacy modules. It is sufficient that today’s sockets are able to be extended to include these features in the future.
It is natural that we want to use the same socket definition for the full range of modules that we will design or integrate. As mentioned earlier, this implies different clock speeds adapted to different levels of bus hierarchy. More significantly, it may also drive the use of several data bus widths and different levels of sophistication in the interface’s dataflow protocol. In particular, a high performance module may support:
- Split transactions, allowing the interconnect (and potentially the module) to efficiently process multiple requests with long or varying latencies.
- Threading, allowing a module to generate or respond to multiple streams (threads) of transactions concurrently, reordering transactions within the threads, but retaining order within each individual thread. This capability is well matched to initiators such as multi-channel DMA controllers and processors and can be exploited by targets such as SDRAM controllers. The complexity of these features is justified for high bandwidth modules that can benefit from them, but is unacceptable overhead for designers of other modules. Hence, we make such features optional and allow multiple bus widths and clock speeds and the socket definition becomes scalable.
3.8 Higher Level Functions
In addition to the signalling level characteristics of the socket described in the previous subsections, it is desirable to include higher level standardisation. This may be provided to aid SoC integration or to support driver software’s exploration of the hardware on which it is running. The most basic example of such standardisation is the allocation of a register – at a fixed offset in a module’s address space, which gives basic information about the module. This information may include the vendor, the module identifier and version number.
3.9 Extensibility and Flexibility
The above considerations apply to any socket. If, however, we consider a definition that is intended to be used by multiple companies, considerations of extensibility become particularly critical.
Firstly, many companies create IP for integration into their own SoC designs. In doing this, they may wish to benefit from the end-to-end control they have by adding domain specific features to an industry standard socket. Texas Instruments’ wireless business unit is an example of such an organisation. We design and integrate modules for wireless handsets and hence, one of the areas we naturally focus on is power consumption. We have therefore, defined innovative proprietary extensions to standard interfaces in several areas, including energy management.
For organisations such as ours, the industry standard must include capabilities for user-defined extensions. The ability to define these extensions within the socket is important in areas such as interconnect generation and verification tools.
Some of our extensions to the interface will be offered to the standards process in the future and we expect to benefit from the availability of additional IP supporting these features as well as from complementary extensions provided by others. The user-defined extensions can hence, be viewed in part as a test bed for additions to the standard.
A second, perhaps more important, area is that of future evolution. The natural goal of standardisation is to enable multiple vendors to design and maintain extensive IP libraries and EDA tool support. Without a socket that ensures continuity, these IP and tool developers will adopt internal abstractions and bridge to sockets based on customer requests. While this approach is feasible, it is clearly not optimal from the perspective of either the developer (who has more work to do) or the integrator (who may suffer area, power or performance penalties). To avoid this defensive scenario and enable native IP and tool creation, a socket must be:
- Sufficiently flexible that it is a natural fit for the task at hand. Use of the industry standard socket must be at least as easy as the current in-house abstraction.
- Simple to gasket (bridge) to current standard and proprietary interfaces (to support interworking of modules and interconnects including legacy elements). Again, bridging must be no more difficult or expensive than with in-house abstractions.
- Based on an extensible foundation – both technically and organisationally – that will support the evolution of the socket and ensure that tools, modules and experience can be transparently reused when the standard evolves. Board level standards such as PCI are good examples of how such an evolution can be orchestrated in a community owned standard. We believe that community ownership is a critical part of socket standardisation and are working in the OCP-IP organisation to ensure that OCP meets these goals.
One critical aspect of socket use is the ability of an IP provider to verify his implementation and to demonstrate the compliance of the module to the standard. Today, there are few mechanisms for providing independent certification of a module and while much simpler, it shares some of the problems of software.
Golden vectors for self-certification, coupled with embedded checkers for SoC verification, are the current state of the art. These can be complemented, as at the board level, by ‘plug fests’: [11].is an indication of how this concept could be applied to the SoC world.
4. OMAP
The remainder of this paper describes the application of the socket approach to Texas Instruments’ OMAP platform [10]. A brief introduction to OMAP from a platform EDA provider’s perspective can also be found in [11].
4.1 The OMAP Family
The emerging 2.5G and 3G wireless markets are introducing new multimedia capabilities to mobile communications, including video messaging, Web browsing, video conferencing, mobile commerce and many others. End users will demand these new performance and security intensive services while continuing to insist on lightweight, small form factor terminals with longer battery life. TI has created the OMAP processor platform to address the needs of high performance, low power consumption and diverse form factors needed for emerging multimedia wireless terminals.
TI currently offers two processors based on the OMAP platform, the OMAP1510 and OMAP710. The OMAP1510 is a low power, high performance applications processor that complements a modem processor and enables enhanced application performance without compromising memory or battery life for all wireless communications standards. The OMAP710 processor is a highly integrated solution for 2.5G devices and combines a dedicated applications processor with a complete GSM/GPRS modem on a single piece of silicon.
All current OMAP devices include an ARM9 (TI925) microprocessor core, extensive DMA, comprehensive memory support and a complete set of peripherals, all supporting an open software architecture and fully integrated and optimised multimedia applications. The OMAP1510 applications processor, shown in Figure 4 meets multimedia design requirements optimally through a two-core approach. The integration of a low power TMS320C55x DSP, (as found in the TMS320C5510 [10]) into the OMAP1510 applications processor allows a high level of processing and low-power consumption not achievable with a general-purpose RISC processor alone.
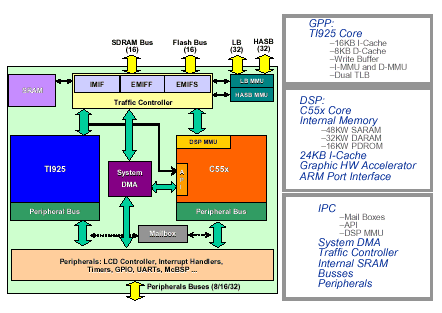
Figure 4: OMAP1510 core engine block diagram and features
TI began shipping OMAP processor prototypes in 4Q 2000, and was delivering products to leading customers in early 2002. OMAP is, of course, evolving and we are constantly improving the processing core as well as developing new chip level products.
4.2 Design Environment
Emerging multimedia wireless terminals have several key design requirements:
- High levels of integration for light weight, small form factor devices.
- Low power dissipation for long battery life.
- Minimised processor clock frequency and code footprint to reduce energy consumption and memory costs.
The final constraint on our design methodology comes from our customers. Handset and PDA manufacturers, such as Nokia, Ericsson, Sony, Sendo, HTC and Palm have announced plans to use TI’s OMAP processor platform. While these companies wish to benefit from Texas Instruments’ extensive IP portfolio and the system definition work that has gone into the OMAP family, it is natural that some of them will want to add their own IP to our chips. Easing this process is a major motivation for our adoption of an industry standard socket.
5. Case Study
5.1 Starting Point
The definition and development of the first generation OMAP products was based on more than 10 years of wireless system expertise. Devices prior to the current OMAP products had the same power, area and time to market constraints we see today and we developed IP and interface standards to support these goals. In particular, we used in-house bus standards for both system (we refer to level-3 or L3, in contrast to a level-2 cache) and peripheral (level-4 or L4) levels of the bus hierarchy.
First generation OMAP devices successfully reused much of the technology from these previous designs and were based almost exclusively on TI developed components. However, it is natural that how we build OMAP devices changes as silicon capability, design methodologies, and the IP market mature. Since, at least initially, the considerations appear somewhat different we will discuss the system/L3 and peripheral/L4 levels of the bus hierarchy separately.
5.2 L4
Our first generation bus standard is known as Rhea or TIPB and epitomises the bespoke, bus-based approach that was common in first generation SoCs. We developed a bus that made use of extensive clock gating and variable data widths to minimise power and area. The approach was successful in these goals and a library of standard components supported asynchronous peripherals. This approach, however, had a number of problems that became more serious as we designed more peripherals, performed more integrations and wanted to use more advanced EDA tools and methodologies.
Using an in-house standard made it hard for us to exchange IP with our customers – importing modules from them was difficult and providing modules for their ASICs was equally difficult, except when they made use of our bus. Finally, there were some modules that we wanted to use as L4 components in some devices and as L3 components in others, other modules such as bridges and DMA had to talk to both. The lack of synergy in the two bus/interface standards made this difficult.
We therefore, introduced OCP initially as a standard for design of IP. We chose OCP after a lengthy evaluation of the available options and after making our choice, we assigned experienced engineers to ensure the adoption was successful throughout the peripheral design community. The IP creation community enthusiastically embraced the new standard and its use spread rapidly.
Since the OMAP core included the TIPB bus bridges, the first step was to use OCP modules in a legacy environment. Despite the fact that we did this first in a complex device designed under significant schedule pressure, it was a relatively painless process. Subsequent devices are native OCP throughout and this has allowed us to significantly simplify the peripheral architecture of OMAP devices by harmonising the various peripheral busses we provided for the different processors and DMA controllers. Integrating modules with legacy interfaces into this native environment is also possible although the modules are naturally being migrated sufficiently fast that this is not a major part of our next generation designs.
Of course, adopting an industry standard interface has made integration of customer provided modules much more straightforward. Even those modules designed with legacy interfaces can be easily integrated by bridging to OCP and connecting to a standard socket. Similarly, our customers— whether or not they have adopted OCP themselves—find it convenient to receive OCP modules from us since we or they can easily provide a gasket to their chosen interconnect. 5.3 L3
Our initial designs were based on an optimised ‘traffic controller’ that included critical memory controllers (SDRAM, execute-in-place NOR flash) as well as the interconnect network. This interfaced to the ARM and DSP through the processor’s own interfaces and to other initiators such as DMA through a simple 32b in-house interface. This design approach was necessary since:
- It was non-trivial to design efficient memory interfaces running at the speed of external components in the low leakage digital processes we were using.
- There was no acceptable industry standard for processor vendors and designers to target.
The subchip included various expansion ports intended for on or off chip devices. Again, these ports used in-house interfaces intended to match the intended uses. Over the various generations of OMAP development, we have found:
- Some of the clock cycle constraints have become less severe since memory speed has not kept up with our digital process development.
- The expansion ports have been used for applications other than those that we intended.
Unfortunately, we cannot fully transition to native interfaces since some IP is not yet available with our chosen interface. However, knowing that this would probably be the case, we chose our socket standard to allow maximum interworking with other standards and can bridge devices from interfaces such as AHB into our OCP environment without penalty.
Our experiences with the c55x DSP core were interesting. Firstly, we found that the DSP needed to support an in-house bus interface in addition to OCP. After some investigation, it became clear that bridging from the dataflow segment of our OCP socket to this other interface was so simple that we could include the bridge in the interface design at no extra cost. This was an encouraging confirmation of our belief that it would be easy to bridge OCP to other interfaces.
Furthermore, as the design progressed it became clear that using OCP would actually save cycles compared with the original interface. This was in part because some of the constraints were removed from the OCP design, but did show that choosing OCP allowed designers to design interfaces that fitted naturally into their blocks.
Finally, the adoption of OCP has made it significantly easier for us to use external IP in the core engine. Whereas, before it would have been a challenge to integrate a memory controller from a third party and unthinkable to use one of the emerging interconnect generators, these options are now possible. One interesting possibility in this area is to make use of OCP’s flexible burst protocol to reduce some of our FIFO requirements and improve performance by using a memory scheduler such as that described in [12].
6. Conclusion
We have presented the motivation for a socket as opposed to dataflow interface standard and attempted to detail some of the key aspects of such a socket. We have shown why we believe that an open, community owned socket standard will enable native interface design interconnection of IP modules and why we have chosen OCP as this standard.
In the second part of the paper we emphasised some of the benefits of such a socket approach by describing its application in TI’s OMAP platform. We also showed how we have phased the adoption of OCP and successfully built chips mixing OCP and legacy modules and infrastructure.
7. References
[1] A. Ferrari and A. Sangiovanni-Vincentallu. “System Design: Traditional Concepts and New Paradigmsâ€, Proceedings of the 1999 Int. Conference on Comp. Des. Austin, Oct 1999.[2] The Future of Wires, Ho R. Mai K.W., Horowitz M.A., Proc IEEE April 2001
[3] Benini, L.; De Micheli, G, Networks on chips: a new SoC paradigm, IEEE Computer Jan 2002
[4] www.vsia.org
[5] www.arm.com
[6] www.sonicsinc.com
[7] www.ocpip.org
[8] Hennessy & Patterson, Computer Architecture A Quantitave Approach
[9] www.socworks.com
[10] www.ti.com
[11]“A Design Chain for Embedded Systemsâ€, Schirrmeister F, Martin G. IEEE Computer Jan 2002
[12]W. D. Weber, “Efficient Shared DRAM Subsystems for SoCs,†presented at Microprocessor Forum, October 2002.
Addendum: About OCP and OCP-IP
A significant challenge in the design of SOC’s is the integration of subsystems that are designed by different designers at different times. Schedule and resource constraints force re-use of subsystems, frequently in contexts different than where the subsystems were originally designed. Commerce in such subsystems (referred to here as Intellectual Property cores, or simply IP cores) between companies expands this problem because there are more IP cores being used in more different contexts.
In a SOC, the IP cores are typically connected using some form on on-chip bus or switch. These interconnects must frequently be enhanced to meet the needs of the specific application serviced by the SOC, e.g. changes are made to the protocol, topology, datapath width, and/or clock frequency of the interconnect. Since each IP core on the chip must communicate via the interconnect, each core must be matched to the interconnect.
In the general case, one may need to match M IP cores to each of N interconnects. Such a task would require the creation of O(M x N) bridges. However, since each bridge would be designed for a specific environment (combination of process technology, clock frequency, wire length and loading, etc.), the bridges would likely need to be modified as the IP cores and interconnects are used in different environments. Creating these bridges is tedious and error-prone, and forms a significant barrier to SOC design.
By adopting a network layering approach, the Open Core Protocol (OCP) greatly improves the situation. OCP occupies a layer between the IP core and the interconnect, defining a standard socket that captures the communication needs of the IP core in a form readily adapted to most interconnects. The result is that, even for existing IP cores and interconnects, the O(M x N) problem becomes O(M + N).
For new cores and interconnects, OCP is even better. This is because it was designed from scratch to isolate the cores from the differentiating characteristics of interconnects. OCP is therefore interconnect-independent. Once the core is isolated from the interconnect, it becomes obvious that the socket should be optimized to match the communication capabilities and needs of the core; the OCP socket is therefore scalable and configurable, so an 8-bit UART has a very simple interface (e.g. 8-bit data, 3-bit address, a handshake signal, and an interrupt line), whereas a multi-bank DRAM controller can have a much more capable interface (e.g. 64-bit data, 28-bit address, pipelined and threaded burst access).
Beyond the data flow advantages, OCP is designed as a true socket. Network sockets encompass entire communication interfaces, and OCP is no different. OCP supports data flow, control flow (interrupts and hardware-hardware signaling), and manufacturing test harness. Furthermore, OCP mimics the ease of connection associated with physical sockets; as a boundary in the on-chip system, OCP signaling is unidirectional and synchronous to the rising edge of the clock to ensure simplified timing analysis and convergence.
Since OCP is interconnect-independent, it is specified as a point-to-point protocol, using a simple master/slave communication model. OCP Masters provide requests, and accept responses. OCP Slaves accept requests and provide responses. An OCP-based system consists of initiators with OCP Master interfaces and targets with OCP slave interfaces. When the interconnect is not simply point-to-point, the shared interconnect (e.g. bus or switch) provides intermediate OCP Slave interfaces to convert requests from initiators into interconnect transfers, and intermediate OCP Master interfaces to convert interconnect transfers into target requests. Cores such as DMA engines that are both initiators and targets also contain both Master and Slave interfaces.
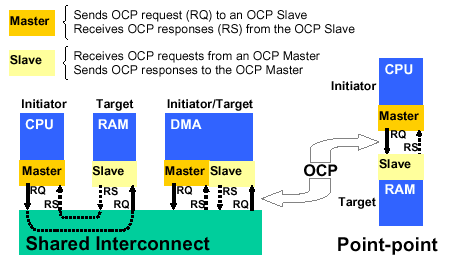
Figure 5: The OCP roles
The data flow characteristics of OCP are very flexible. While the basic transfer types are the standard read and write, optional commands support atomic read-write pairs and broadcast/multicast writes. OCP supports both Master and Slave flow-control, on both requests and responses, and variability in address width, data width, transfer pipelining, burst types, and execution ordering via hardware threading. OCP control signaling is equally flexible, supporting variable field widths, and several types of specified (e.g. error and interrupt) and unspecified fields.
Finally, OCP provides a set of timing templates that allow the IP core designer to characterize their interface timing based upon expected interconnect timing parameters. This allows the interconnect bridges to frequently operate in a combinational fashion, so use of OCP typically adds no cycles of latency to IP core accesses versus traditional approaches.
OCP-IP
The OCP International Partnership Association, Inc. (OCP-IP) was formed in December 2001 to promote and support the open core protocol (OCP) as the complete socket standard that ensures rapid creation and integration of interoperable virtual components. In addition to Sonics, Inc., the inventor of the OCP technology, OCP-IP's founding members and initial Governing Steering Committee participants are: Nokia [NYSE: NOK], Texas Instruments [NYSE: TXN], MIPS Technologies [NasdaqNM: MIPS], and United Microelectronics Corporation [NYSE: UMC]. OCP-IP is a non-profit corporation focused on delivering the first fully supported, openly licensed core-centric protocol that comprehensively fulfills system-level integration requirements. The OCP facilitates IP core reusability and reduces design time and risk, along with manufacturing costs for SOC designs. For additional background and membership information, visit www.OCPIP.org.
Authors
Pete Cumming received a B.Eng (1 st class honours) from the university of Sheffield, England in 1990. He worked for SGS Thomson Bristol for 5 years, first as a CPU designer then as team leader for CPU microarchitecture, implementation and verification. Following work on hard disk drive signal processing at Analog Devices he joined Texas Instruments in Nice France where he manages the SoC and processor architecture team.
Franck Seigneret earned an engineering degree in Electronics and Digital Signal Processing, from the Physics and Electronics Institute of Lyon, France in 1987. He worked for Getris Images, France, on professional video and graphics platforms, first as a design engineer, then leading the hardware development team. From 1997 he worked for STMicroelectronics as the architect leader on the definition of 2D-graphics acceleration for set-top boxes. He joined Texas Instruments, Nice, France in June 2001, where he is responsible for chip level architecture in the Wireless Terminals Business Unit.
1 Courtesy of Sonics Inc