
Kazuyoshi Kohno*,and Nobu Matsumoto*
* Toshiba Corporation, Kawasaki, Kanagawa, Japan
** Toshiba Electronics Europe GmbH, Duesseldorf, Germany
Abstract :
This paper presents a new hardware/software partitioning methodology for SoCs. Target architecture is composed of a RISC host and one or more configurable microprocessors. First, a system is partitioned globally, and only then it is partitioned locally. In the local partitioning, the co-synthesis technique is used. We have applied this methodology to an MPEG-2 decoder and obtained good results such as achieving a 36% performance improvement by co-synthesis.
1. Introduction
Recent advances in semiconductor technology facilitate the integration of many million gates on a single chip and result in the integration of Systems on Chip (SoC). Typical examples of SoC applications can be found in the multimedia domain and in intelligent transport systems. In those applications, generally, large amounts of data must be processed in parallel. However, performing such processing by software running on a high-performance processor or only by hardware is not efficient except for a few specific cases.An optimal combination of hardware and software and an optimal system partitioning into hardware and software is most desirable.
Studies of hardware/software co-design have been made for a long time. The first methodology is the one of Intellectual Properties (IP) re-use. As it¡¯s related technology, studies of interface synthesis which is required in building a system based on the IP have been made [1][2]. In this methodology, however, there is a limitation that data processing which is not covered by the existing IP is done only by software. As another co-design methodology, a method of partitioning a system into hardware and software directly from its specification description, so called co-synthesis, has been studied [3][4][5]. In conventional co-synthesis performance degradation was observed, since the target-architecture was composed of general-purpose processors and a bus (see section 2 for further details). As an attempt to overcome such problems, work on configurable processors [6][7][8], processor generation and retargetable compilers ([9][10][11]) has been made as well. The issue of these studies must be how to achieve global optimization by avoiding ending up only in local optimization at the time of hardware/software partitioning.
This paper presents a new hardware/software partitioning methodology with a RISC host processor and one or more configurable embedded microprocessors for time critical tasks. This methodology aims at unloading the software running on the host from compute intensive tasks by dedicated hardware accelerators. The major part of the application runs on the host processor, while time critical data processing parts are executed on one or more deeply embedded heterogeneous processors based on a configurable architecture. Since SoCs are often highly cost-sensitive, optimization of silicon area has the same level of importance as design efficiency to accelerate the SoC development process. Conventional approaches for hardware-software partitioning focused mainly on EDA aspects, such as algorithm and design flow improvements, which are however not sufficient for the development of cost-efficient SoCs. Therefore, we have developed a flexible hardware platform based on a configurable processor architecture with various hardware extensions and a hierarchical bus structure[12][13][14]. An EDA based partitioning methodology has been developed to support this platform.
Our methodology is composed of two stages, which we call ¡°global partitioning¡± and ¡°local partitioning¡±. Although a co-synthesis methodology is used in the local partitioning phase, the problems mentioned earlier are solved by making the target hardware architecture configurable and by improving the scheduling of the compiler .
In Section 2, we explain related conventional studies, especially those of co-synthesis in more detail. Section 3 discusses the presented partitioning methodology and its target architecture. The application results of this methodology are described in Section 4 and Section 5 is the summary of this paper.
2. Related Work on Co-Synthesis
The need for co-designing hardware and software has long been pointed out for the development of SoCs [15] and co-design tools have been developed by many projects.
Co-design can be roughly classified into two approaches, software oriented partitioning [4][16] and hardware oriented partitioning[3][5]. The difference between the two is whether the functional specification model is written as a software model or hardware model.
Most methods are focussing on hardware/software partitioning techniques to transform functional specifications into an optimal system architecture. Studies of performing optimal hardware/software partitioning by applying proprietary algorithm or methodologies are under way. The method aiming at automatically generating a software model that can be cross-compiled and a hardware model that can be synthesized at a high level by applying the hardware/software partitioning algorithm is called co-synthesis [3][4][5]. One of the merits of co-synthesis is that a hardware model and a software model can be partitioned with little user¡¯s intervention. However this feature reduces visibility to the designer and hence controllability. Some co-synthesis methods take the phased approach, where certain stages are defined in the process to create an optimal system architecture from functional specifications, in which designers can refine the functional specification [17][18]. The merit of this approach is that architectural limitations can be revealed at intermediate stages thus identifying specification problems early that would otherwise come to the surface only in later stages.
As stated above, many methods for system development have been described in the literature. But applying those methods to actual SoC designs is still difficult due to inherent limitations.
One limitation is that the design process is based on a target- architecture with general-purpose processors and a bus on which ROM, RAM, hardware accelerators, co-processors, etc. are allocated. It is very hard to estimate execution cycles for the hardware units, because the bus is shared by various data transfers.
It is preferable to use a model that is executable on the target-architecture as specification, because reusability of existing specification models is improved. Further, it is preferable that the specification model is a software model that can be cross-compiled. The reason for that is that refinement of the software model will directly influence the performance of the final system. In conventional co-design methods, a specification model cannot be cross-compiled because languages such as expanded C language or proprietary languages were used such that the specification model can be described in both a software model and hardware model. Under critical conditions, the difference between the evaluation result where hardware/software partitioning of the specification model was done and the one where only an execution model was used is considerable, and it is very likely that a time consuming repetition of the partitioning process is required.
Finally, despite of recent remarkable developments of EDA tools, hardware design is still a time-consuming task. That is why it is important that a system simulation is fast and accurate. To that end, not only the verification on the RTL (co-verification) level but also on a higher level model such as C-based (co-simulation) must be done. However, in co-simulation methods, where basic blocks [19][20] of conventional co-design projects are used, the achievable accuracy is not quite satisfactory.
3. RISC Plus Configurable-Processor Platform Methodology
3.1. Top-Down Design Methodology for SoCs
To begin with, let us explain the top-down design methodology for SoCs that is the basis of this entire methodology. In this top-down methodology the hardware/software partitioning of the system is performed in two stages :¡¡(1) globally and (2) locally. Then the partitioned system is mapped and implemented on the hardware platform, which will be explained in the next section to obtain the desired SoC. Fig. 1 illustrates the concept of this top-down design methodology. The following is the detailed explanations of the global and local partitioning.
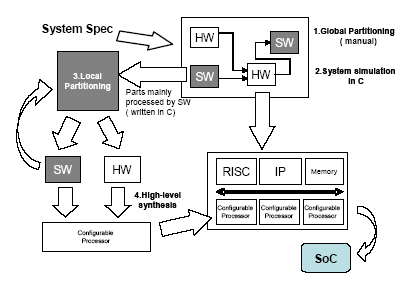
Fig 1. SoC Top-Down Design Flow
(1) The global partitioning
The global partitioning is done manually based on the heuristics described below.
SoC for digital consumer applications generally consists of two parts: (a) the data processing part, and (b) the application part that controls data processing and communicates with the outside. Therefore, at first the entire function of the SoC is partitioned into the data processing and the application part.
In the application part, communication with the outside is usually done based on well defined standards, so it can be implemented by an optimised IP block that meets the given standard. On the other hand, the application itself is usually software-oriented and it can be implemented by software running on a processor. Usually, the data processing part is composed of multiple tasks. By bringing those with common I/O data together, the tasks are partitioned into several groups, where each group of tasks is implemented on one processor. In addition, there are generally tasks that require high throughput and therefore are obviously suited for hardware acceleration. After having identified such hardware tasks they can be removed from the software model and implemented as hardware. If done well this hardware can be shared among different tasks in a time-multiplexed manner.
After partitioning the system based on the above heuristics, the system operation is verified by executing a system simulation. For high-speed simulation, it is desirable to create a hardware model based on a highly abstractive API.
(2) The local partitioning
After the global partitioning, we partition each task locally based on the greedy heuristics shown below. The procedure for the partitioning is shown in Fig. 2.
First, we describe the task as a C program (Step 1). Then, we execute the program to evaluate if it achieves the required performance (Step 2). If it does not, we obtain profile information (Step 3). We then change the implementation of the part which was indicated by the profile information, that its processing is the heaviest to the hardware (Step 4). The way of this change will be described in Section 3.3. After that, we execute the program again and check if it meets the required performance (Step 5). By repeating Step 3 to 5 until the required performance is achieved, the partitioning is accomplished.
Generally, it is highly likely that only the partitioning based on the greedy heuristics ends up in the local optimum far from the global optimum. In our chosen partitioning methodology, this problem is avoided by partitioning a system in a global manner first.

Fig 2. Local Partitioning Flow
3.2¡¡SoC Platform based on RISC Host and Configurable Microprocessor
In this section, we explain the SoC design platform based on the top-down design methodology explained in section 3.1. Fig. 3 shows an architecture block diagram which represents a general platform for SoCs supposed to process digital audio and video. This architecture is composed of two major blocks corresponding to the application part and data processing part explained in the previous section, and a memory shared by these two blocks.
The application part is composed of a RISC processor, which will act as a host, and peripheral IP. The performance required for the RISC processor varies depending on the target SoC, therefore a suitable RISC processor is chosen on a case by case basis. For example, a 32-bit RISC processor was chosen for a low-end SoC for DVD playback and a 64-bit RISC processor was chosen for HDTV and PVR (Personal Video Recorder) SoCs. Similarly, IPs for I/O are chosen from USB1.1/2.0, IEEE1394, etc. according to the requirement of the target SoC.
¡¡Since high performance specific to each task is required for the data processing part, it has a heterogeneous architecture composed of customized processors which were designed based on configurable processors and hardware modules. As a configurable processor, MeP (Media embedded Processor£©[12] is used.
Fig. 4 shows a block diagram which illustrates the basic architecture of MeP SoC. In this processor, each MeP module in MeP SoC is customized for a specific task. A MeP module is composed of a MeP core, which is a processor core, and extension units, and it allows optional instructions such as fast multiply-add instructions and modification of the size or configuration of instruction cache/RAM and data cache/RAM. It also allows users¡¯ own instructions or hardware engines to be attached to the MeP core as extension units. The local partitioning, to be explained in 3.3, is applied to the customization of MeP modules. The feature of the MeP module is that it contains a DMA controller, which enables a MeP module to function as an independent functional block including data transfer. The configuration of the data processing part can be changed module by module. For example, in the case of the SoC for DVD, the data processing part is composed of MeP modules for audio decoding and video decoding, and in the case of the SoC for PVR, it is composed of MeP modules for audio CODEC, video CODEC and motion prediction.

Fig. 3 Digital multi media platform

Fig. 4 MeP architecture
3.3. Local Partitioning -- Co-Synthesis Methodology
Now, let us further explain the local partitioning the outline of which was given in 3.1. The methodology of the local partitioning is twofold: to make use of the addition of users¡¯ own instructions, and to make use of hardware engines. Since the former has already been explained in [14], we focus on the latter here. The co-synthesis technology is applied to the latter methodology.
The conventional co-synthesis had limitations mentioned in Section 2. Therefore, we have developed a new co- synthesis system in which the target-architecture itself is optimized. We have prepared a dedicated bus for hardware extensions to the processor. In the co-simulation phase, it is easy to estimate execution cycles of hardware extensions connected to the dedicated bus and the estimation results of our system have good accuracy.
We took a software oriented approach and decided to describe the specification model in C language because the specification model can be used as a C program as it is. Also, the C compiler is modified to use latency of hardware units for code scheduling. While the processings of the hardware unit are being executed, the processor executes instructions which are not related to those processings.
Finally, we determined to generate a C-based hardware model for verification from the C program to conduct verification on the C-level using Instruction Set Simulation (ISS). This C-based hardware model becomes the hardware architecture specification and it is converted into RTL by our high-level synthesis tool. This high-level synthesis tool is also able to automatically generate an interface to the bus of the target-architecture and a direct access interface to the local memory in the processor module if necessary.
With the combination of the direct access interface and the compiler¡¯s ability of code scheduling, our co-design system allows reducing the overhead generated during the communication between the hardware model and software model to a minimum.
From here, we explain our co-synthesis system Hegen. Hegen is a tool which requires a software model written in C language as input, and automatically generates a C-based hardware model from a part of the software model (to be specific, functions) based on the designer¡¯s simple instructions. In addition to that, Hegen modifies the software model and incorporates the device driver to control the C-based hardware model automatically, which makes system design free from human error and more efficient.
As shown in figure 5, Hegen can be positioned as the support tool for conducting system design in a top-down style. Also, it enables the re-design where part of a software model is transformed to a hardware model in the pursuit of further improvement of performance, since the specification model of a existing system can be used for input as it is.
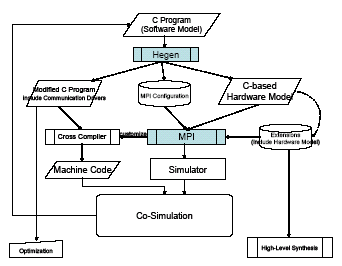
Fig. 5 System structure.
A design flow with our Co-Design system is as shown in Figure 6
At this stage, hardware engine models, device drivers for control, setup files for generating the compiler, and setup files for generating the simulator, etc. will be generated automatically. Note that none of them have to be written manually.
Hegen will examine the arguments of functions specified for the hardware model, return values, global variables being used, and their I/O attributes, and then assign them to each port (registers and memories mapped for I/O) on MeP. The device drivers to be used within a C program environment will be programmed so that the values can be written in and read from the assigned ports. Also, the hardware models will be programmed so that read/write of their values can be performed through the API of the simulator.

Fig. 6 Design flow with Hegen
Here, referring to a simple example, we explain how the C program is modified with Hegen. A function named muladd that performs summing of products is prepared as an example.
{
return a*b+c;
}
Where muladd is specified as an objective of transforming to a hardware model, Hegen will analyze that muladd takes inputs of a, b, and c and takes outputs of their return value. Also, if the MeP's control bus address space on and after 0x2000 is free, the address, 0x2000, will be assigned for starting the hardware engine, and after 0x2001 will be assigned for a, b, c, and the return value.
Then, the contents of muladd will be rewritten to form a device driver as follows using two functions, one of which is stcb(data,address) for writing data in a specified address and the other is ldcb(*data,address) for reading data from a specified address.
First load the arguments (a,b,c) to be used as input onto the address space.
Then, initiate the hardware engine.
Finally, the data to form the output value will be read from the address space. __order is a macro used to transfer the latency of hardware engine to the compiler. In this case, latency of the hardware engine is 14.
{
int ret;
stcb(a,0x2001); // Set the value
stcb(b,0x2002); // to the hardware engine.
stcb(c,0x2003); //
__order (
stcb(1,0x2000), // Initiate the hardware engine.
ldcb(&ret,0x2000), // Read the results.
14); // Latency of the hardware engine
return ret;
}
Within a C program, it is possible to use the hardware engine using the function named muladd, which has been rewritten into a device driver. Since this operation is performed automatically, it is unnecessary to manually rewrite the C program at all.
On the other hand, the hardware engine model corresponding to this device driver is generated as a derived class of the class defined in the simulator. This model is automatically linked to the simulator when the simulator is customized.
4. Application Results
In this section, we explain the single-chip DVD player SoC that was designed based on the top-down design methodology for SoC explained in Section 3.
4.1. Single-Chip DVD SoC, ¡°TC90600FG¡±
(1) The outline of the DVD player system
TC90600FG is a single-chip SoC on which a read channel processing circuit for the DVD player system, a digital servo circuit, a control micro controller and MPEG2 audio/video decoders are loaded.
Figure 7 is a block diagram of the DVD player system with TC90600FG. The DVD player system is structured with a head amplifier, a motor driver, 64Mbit SDRAM, 8Mbit Flash ROM and a sub-microcomputer for an infrared remote-control interface/front panel display.
(2) The outline of the hardware of TC90600FG
Since TC90600FG was developed as a key component for DVD players, it is equipped with all functions required for a DVD player system. In addition, its circuit scale, chip size, and power consumption were minimised in an attempt to meet the ever-increasing demand for lowering system cost. In order to create the DVD player system with a small number of components, an analog front-end processing circuit, a RISC for control and a back-end processing circuit implemented by the configurable media processor MeP were integrated into one chip.
As the RISC processor for control, we have adopted TX19, which is a 32bit RISC processor core that was developed based on the MIPS compliant RISC microprocessor R3000A with the addition of a high code efficiency extension instruction set MIPS16 ASE(Application Specific Extension).
In order to create a DVD player system with lowest possible cost, the UMA(Unified Memory Architecture) requiring a single external 64Mbit SDRAM has been adopted. In the external DRAM, frame memory for MPEG2 video decode processing and user area are allocated.
Two MeP modules are used on the TC900600FG SoC. One is dedicated to the audio decode processing and the other performs the processings other than that such as track buffer control, copy-protection processing, sub-picture decode processing, MPEG2 video decode processing, OSD (On Screen Display) processing and video scaling processing.
Table 1 shows the specification of TC90600FG, and Table 2 shows the MeP core configuration of the MeP module for image/picture processing and the one for audio processing.
(3) The outline of the software of TC90600FG
In TC90600FG, the software of the SoC system for DVD players is hierarchically structured with the following three layers in descending order.
(a) The navigation engine layer
(b) The presentation engine layer
(c) The task engine layer
The relation between the software structure and each layer is shown in Figure 8.
The navigation engine layer controls GUI (Graphical User Interface), infrared remote-control interface, front panel display, disk tray and reproduce condition setting. This layer runs on TX19 and is connected to the presentation engine layer by calling the function defined by the API (Application Programming Interface).
The presentation engine layer controls each task engine in order to execute DVD reproduction according to the API instructions from the navigation engine layer. This layer is composed of a presentation engine section that runs on TX19 and another presentation engine section that runs on MeP. The presentation engine section on TX19 has the function of handling the command issued by the upper layer through API to the presentation engine section on MeP and also returning the required task status to the upper layer. On the other hand, the presentation engine section on MeP has the function of controlling the command issuing to each task and its timing, as well as controlling tasks.
The task engine layer can be roughly divided into two engines: the read channel processing/servo control engine and the audio/video processing engine. The read channel processing/servo control engine is composed of a dedicated hardware and a firmware that controls this dedicated hardware from TX19. The audio/video processing engine is composed of a firmware that runs on the two MePs explained in (2) and a dedicated hardware connected to those MePs. The audio/video processing engine is also composed of multiple task engines. To be specific, they are track buffer, program stream decoder, MPEG2 video decoder, sub-picture decoder, audio decoder, etc. The interface between the presentation engine layer and each task engine is performed through the communication area in memory that stores the command to each task and the status of each task.

Fig. 7. Block diagram of DVD player system
4.2. Partitioning Results of TC90600FG
Now, we present the results of the hardware/software partitioning of TC90600FG.
Of the DVD players¡¯ functions, the application part such as optical disk drive control, the data processing part control and user interface control are realized by the software that runs on the TX19 32bit RISC processor.
At the same time, the data processing part of the DVD players¡¯ functions, that is, read channel processing, digital servo, track buffer control, copy-protection processing, sub-picture decode processing, MPEG2 video decode processing, OSD (On Screen Display) processing, video scaling processing and audio decode processing are realized by the dedicated hardware and the two MeP modules which have different configurations.
We explain part of the application results of hardware/software local partitioning methodology of TC90600FG MeP module in detail in the next section.

Table 1. Specification of TC90600FG

Table 2. Configuration of MeP modules in TC90600FG
We applied a two-stage partitioning methodology to be presented here to the video decode task (hereinafter called VDec) used in TC90600FG. As mentioned in the preceding section, in the case of TC90600FG, first the hardware such as IDCT/IQ was partitioned at the global partitioning stage. However, the VDec C program after the global partitioning fell short of the required performance by more than 10 %. Therefore, the local partitioning methodology was applied to this program.
The profile result of the VDec simulation execution indicated that decoding of motion vectors and predicated motion vectors (hereinafter called PMV) consumed a lot of processing time. Therefore, we have shifted the implementation of PMV from software to a dedicated hardware engine. First we created a C simulation model of PMV and confirmed its operation. Then we transformed the C simulation model into RTL using high-level synthesis. With this transformation, the speed of VDec was improved by 19% and the required performance was achieved.
Thus far we have explained what was done in the practical SoC design process. We tried to further speed up this VDec by applying the co-synthesis technology.

Fig. 8. Software architecture of TC90600FG
Between this PMV hardware engine and the process of decoding the motion vector, data exchange is executed several times. It means that some of the processes for decoding the motion vector can be added to the PMV hardware engine.

Fig. 9 Function hierarchy of C program
Therefore, we re-designed the specification model in which the hardware model of PMV hardware engine was incorporated as part of the software model as it is by making good use of the feature of the C-based hardware model. The results are shown in Table 3.

Table 3 Simulation Results
As shown in Table 3, better performance than that of ¡°Default¡± case where only a software model is used has been observed in all the cases. In addition to that, the performance has been improved by 36% at the maximum compared with the conventional PMV hardware engine that has only the PMVEngine as a hardware model.
5. Conclusion
This paper presents the top-down design methodology based on the two-stage partitioning and the partitioning methodology by co-synthesis. We have successfully applied our method to the development of an MPEG-2 decoder task. In terms of local partitioning, we applied the co-synthesis method to motion compensation of a video decode task and 36% performance improvement could be observed for this task.
Based on our partitioning methodology and co-synthesis method from C language, an accurate performance evaluation at early stages of the development is possible and thus competitive and effective SoC design becomes feasible.
List of Key-Words:
Hardware/software partitioning, Configurable processor, RISC, co-synthesis from high level language, SoC, multi media, MPEG2
REFERENCES
- [1]P. Chou, et al., Interface Co-Synthesis Techniques for Embededded Systems, in Proc. of ICCAD, 1995, PP.280-287
- [2]K. V. Rompaey, et al., CoWare ¨C A design environment for heterogeneous hardware/software systems, in Proc. of European Design Automation Conference, 1996, PP. 252-257
- [3]Rajesh K. Gupta, Co-Synthesis of Hardware and Software for Digital Embedded Systems, Kluwer Academic publishers, 1995
- [4]R. Ernst, J. Henkel, T. Benner, Hardware-Software Co-Synthesis for Microcontrollers, IEEE Design & Test of Computers, Vol.10, No.4, Dec. 1993, pp.64-75.
- [5]Hardware-Software Co-Design of Embedded Systems, The POLIS approach, Kluwer Academic Publishers, 1997.
- [6]ARC Inc. http://www.arccores.com/
- [7]R. Gonzalez, Xtensa: A Configurable and Extensible Processor, IEEE Micro, March/April 2000, pp.60-70.
- [8]Y. Kondo, et al., A 4GOPS 3Way-VLIW Image Recognition Processor Based on a Configurable Media-processor, Proc. of ISSCC 2001, Feb. 2001, PP.148-149.
- [9]J. Sato, M. Imai, et al, PEAS-I: A Hardware/Software Codesign System for ASIP Development, IEICE Trans. Fundamentals, E77-A(3), Mar. 1994, pp. 483-491
- [10]H. Tomiyama, et al., Compiler Generator for Software Codesign, Proc. of 2nd Asia Pacific Conference on Hardware Description Languages (APCHDL'94), Oct. 1994, pp.267-270.
- [11]ACE, The Cosy compiler development system : http://www.ace.nl/products/cosytech.htm
- [12]T. Miyamori, A Configurable and Extensible Media Processor, Embedded Processor Forum, 2002.
- [13]S. Ishiwata, et al., A Single-Chip MPEG-2 Codec Based on Customizable Media Microprocessor, Proc. CICC 2002, May 2002, pp.163-166.
- [14] Mizuno et. al. "Design Methodology and System for a Configurabel Media Embedded Processor Extensible to VLIW Architecture"; ICCD Conference, 2002
- [15]W. H. Wolf, Hardware-Software Co-Design of Embedded Systems, Proc. of the IEEE, Vol. 82, No.7, July 1994, pp.967-989.
- [16]B. Dave, G. Lakshminarayana, and N. K. Jha, COSYN:Hardware-software cosynthesis of embedded systems, In Proc. 34th DAC, June 1997, pp. 703-708.
- [17]G. F. Marchioro, J. M. Daveau, A. A. Jerraya, Transformational Partitioning for Co-Design of Multiprocessor Systems, In Proc 17th ICCAD'97, pp.508-515, 1997.
- [18]L. Cai, D. D. Gajski, M. Olivarez, P. Kritziger, C/C++ Based System Design Flow Using SpecC, VCC and SystemC, CECS, UC Irvine, Technical Report CECS-TR-02-30, June 2002.
- [19]R. Ernst, W. Ye, Embedded program timing analysis based on path clustering and architecture classification, In Proc. 17th ICCAD'97, pp. 598-604.
- [20]S.Malik, W.Wolf, Y.S.Li, T.Yen, Performance Analysis of Embedded Systems, NATOASI, Workshop on Hardware-Software Co-Design, Tremezzo, Italy, 1995.