
by Ken Umeno
Communications Research Laboratory and ChaosWare, Inc. - Japan
Abstract :
One of the fundamental issues in security technology is the high-speed encryption with a limited hardware. There is a strong demand for such high-speed encryption in many applications such as copyright protection of digital contents distributing over broadband networks. Here, we introduce our IP core based on our new stream cipher called VSC (vector stream cipher), which are suitable for implementing high-speed encryption with highest efficiency.
INTRODUCTION
The following table shows the comparison between AES, MISTY and VSC based hardware implementations. Our VSC has the highest encryption speed such as 25.62Gbit/s in the world.
Table 1: Three Cipher Processors
Such high-speed features of VSC come from full-scalable encryption algorithm as described as follows.
VECTOR STREAM CIPHER AS FULL-SCALABLE CHAOTIC ENCRYPTION
Our VSC is a kind of stream cipher. Thus, the main component of VSC is key generations.VSC uses a patented algorithm of generating random-vector generations based on skew product transformation [3]. Let f(p,x) be a transformation from n bit to n bit with 2n parameters p. Two-dimensional map composed from the skew product of f(p,x) is given by
Three-dimensional map composed from the successive skew products of f(p,x) is given by
We can generalize to arbitrary m dimensional map by using m-1 successive skew products of f(p,x). It is known in ergodic theory that if f(p,x) has the uniform invariant measure, the invariant measure of the skew product transformation is also uniform. We use this fact to generate arbitrary dimensional uniform random numbers. Such f('E,'E) can be constructed by
Here, Mod(p,4) is defined as a residue of the devision of p by 4.
f(p,x) is known to be a permutation polynomial (one-to-one mapping over GF(2n)) whith any parameter p [4]. Because permutation polynomials have a uniform invariant measure, we can generate arbitrary many dimensional uniform distributions from skew product of permutation polynomials. It is noted that
then f(p,x) is a permutation polynomial used in the well-known block cipher algorithm RC6 [5].
We combine this successive skew product transformations and bit rotation in our VSC. In this case, 1 bit difference on the initial data can give a global difference which can be measured by a large Hamming distance. Thus, this mappings over a finite field can be regarded as chaotic mappings over a finite field. Such chaotic dynamical system over a finite field have not been a subject of research to date. Thus, we can categorize a dynamics given by a polynomial mapping over the finite field into « digital chaos ». Our algorithm can be classified into a chaotic encryption algorithm based stream cipher. Thus, we call chaotic encryption algorithm VSC.
FULL SCALABILITY
We construct our IP core of VSC based on VHDL. Figure 1 clearly shows FPGA implemented scalability of VSC.
We use DDR-SDRAM Evaluation board (Tokyo Electron Device, Ltd.) with a FPGA (Xilinx Vertex II XC2V1000). If encryption speed is 200Mbps, gate size can be less than 10K, which is very efficient and suitable for implementing security in power limited mobile devices.
Table 2 shows more detail evaluation of implementation efficiency in FPGA when we use a Heron-FPGA board (Hunt Engineering, Ltd.) with the same FPGA. The VSC encryption speed data of Table 1 showing 25.62Gbps corresponds to the implementation of VSC 512 (512 bit key length) into the Heron-FGPA evaluation board in Table 2. In this experiments, implementation efficiency is always greater than 100 Kbps/Gate and less than 200 Kbps/Gate, which shows full-scalability and high implementation efficiency of VSC's IP.
'@'@'@
Figure 1'VSC's Scalability in FPGA Implementation'iKey Length'@vs Gate Size 'j
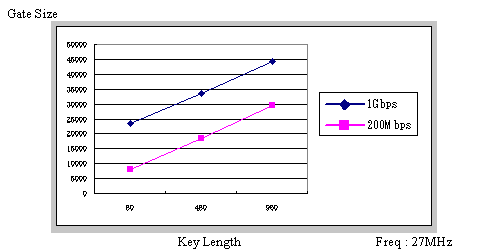
Table 2: VSC Implementation Result Based on Heron-FPGA Evaluation Board
We also evaluate randomness property of VSC-generated bit sequences using the NIST Statistical Test Suite for Randomness called NIST 800-22 [7]. In 128bit key length encryption, VSC-based generated random numbers shows a better randomness property than AES and SHA-1-based generated random numbers. The detailed data is given in Ref. [8].
REALTIME HDTV ENCRYPTION
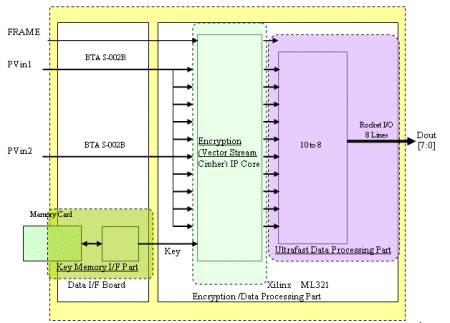
As an application of such high speed encryption, we develope a platform for realtime HDTV signal encryption for the first time. The schematic blockd diagram for realtime encryption system of HDTV signals is given in Fig. 2. In this system, we use our IP core of vector stream cipher as a cipher processor of HDTV. Since one HDTV signal transmission speed is 1.485 Giga bit/s, the total throughput for transmission speed is 14.85 Giga bit/s by generating 10 same HDTV signals as input data (PVin1 and PVin2) . This system encrypts HDTV data and decrypts encrypted data into the original HDTV data in realtime by using 14.85 Giga bit/s vector stream cipher processors implemented in Xilinx-Vertex II Pro. In the Ultrafast Data Processing Part in Fig. 2, we use the 10 serial data of 20bit size with a clock frequency 74.25MHz. Thus, we obtain the following formula for the speed
of encryption, decryption and transmission :
Figure 2: Schematic Diagram for Encryption/Data Processing Function of HDTV Encryption System.
Since we use 8 series Rocket I/O for transmission of encrypted HDTV signals, the 10 to 8 transformation is used for encryption at the transmitter board and the 10 to 8 transformation is used for the decryption at the reciever board. The functional block diagram is given in Fig. 3. Here, IP core of vector stream cipher is implemented in the crl_scr_tx (t_crl) part. The clock frequency difference between the 74.25 MHz from the Data I/O board and
the 74.25 MHz generated by deviding the 148.5 MHz external OSC by two is adjusted in tx_fifo blocks.
Figure 3 : Block Diagram for Encryption/Data Processing Function of HDTV Encryption System.
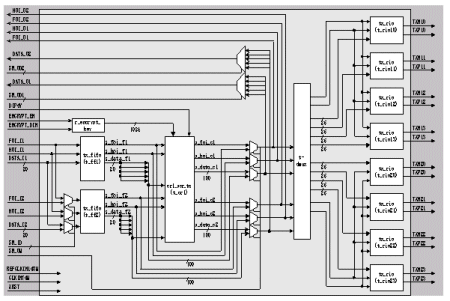
Figure 4 : More Detailed Block Diagram for tx_fifo.

The tx_fifo block is shown in Fig. 4. Timing chart of this tx_fifo module is depicted in Fig. 5.
Figure 5 : Timing Chart for tx_fifo Block

Figure 6 : Realtime HDTV Encryption System with Half-Image Encrypted

Figure 7 : Realtime Bamboo-Blind Type HDTV Encryption System.

Since our encryption IP is implemented in FPGA, we can provide various type of encryption of HDTV. For example, a half-image HDTV encryption system is depicted in Fig. 6 and a bamboo-blind type HDTV encryption is depicted in Fig. 7 while those systems use the unique encryption/decryption processor. This shows that our vector stream cipher IP cores are implemented as reconfigurable encryption processors with retaining multi ten Giga bit/s processing speed.
CONCLUDING REMARKS
We introduce an IP core of high-speed stream cipher called VSC with some theoretical backgrounds and its applications to broadband security of HDTV encryption. VSC VHDL IP is shown to attain 25.6 Giga bit/s encryption speed in FPGA, which seems to the world record for encryption speed. While VSC can attain more speed in ASIC, VSC's implementation efficiency in FPGA is constantly very high which shows full scalable features of our IP. This IP core can be used for high-speed encryption as well as low-power encryption in mobile terminals. For demonstration purpose of showing such high-performance encryption, this IP core was used for the first experiment of real-time HDTV encryption, transmission and decryption at 14.85 Gbit/s which corresponds to the speed that 10 series of HDTV signals can be encrypted in real-time. The speed of 14.85 Gbit/s is also the fastest for encryption, transmission and decryption in the world to the author's knowledge [9]. Therefore, we conclude that our IP of VSC(vector stream cipher) is very suitable for realizing strong security of broadband networks such as 10Gbit/s IP networks of the near future.
ACKNOWLEDGEMENT
The author thanks Dr. T. Iida, Dr. K. Hasuike, and Dr. F. Kubota and Mr. F. Sawada of Communications Research Laboratory (CRL) for strong supports to this IP development and our making up a start-up company ChaosWare, Inc in CRL which can add potential market values to this IP core.
REFERENCES
[1] http://www.broadcom.com/products/5841.html
[2] http://www.security.melco.co.jp/SecWWW/category1/Japanese/MISTY1ipj.htm
[3] Introduction of Japanese Patent No. 3030341 (Inventor: K. Umeno)
http://www2.crl.go.jp/kk/e414/shuppan/kihou-journal/journal-vol49no3/05.pdf
[4]R. L. Rivest, Permutation Polynomials modulo 2^w, in Finite Fields and their Applications Volume 7 (2001), pages 287--292.
[5] ftp://ftp.rsasecurity.com/pub/rsalabs/rc6/rc6v11.pdf
[6]K. Umeno, « Scalable Chaotic Cipher and its Performance Evaluation of Hardware Implementation »,
The 5-th LSI IP Award Paper (2003, Nikkei Business Publishing, in Japanese).
http://ne.nikkeibp.co.jp/award/papers/2003_co02.pdf
[7] A Statistical Test Suite for Random and Pseudorandom Number Generators for Cryptographic Applications,
(October 2000, Revised May15 2001, NIST)
http://csrc.nist.gov/publications/nistpubs/800-22/sp-800-22-051501.pdf
[8]K. Umeno, S. Kim and A. Hasegawa, « The fastest cipher VSC : evaluation of its cryptographic randomness and implementation efficiency » (Lecture Note of invited talk at 21COE security seminar at Chuo-University,
April 16,2003)
http://www.21coe.chuo-u.ac.jp/security/umeno2003-04-16/umeno.pdf
[9] http://www2.crl.go.jp/pub/whatsnew/press/030415-1/030415-1.html
Communications Research Laboratory and ChaosWare, Inc. - Japan
Abstract :
One of the fundamental issues in security technology is the high-speed encryption with a limited hardware. There is a strong demand for such high-speed encryption in many applications such as copyright protection of digital contents distributing over broadband networks. Here, we introduce our IP core based on our new stream cipher called VSC (vector stream cipher), which are suitable for implementing high-speed encryption with highest efficiency.
INTRODUCTION
The following table shows the comparison between AES, MISTY and VSC based hardware implementations. Our VSC has the highest encryption speed such as 25.62Gbit/s in the world.
Table 1: Three Cipher Processors
| Cipher Processor | BCM5841 [1] | MISTY1 801 [2] | VSC (The present IP) |
| Encryption Speed | 4.8 Gbps | 2.8 Gbps | 25.62 Gbps |
| Type of Hardware | ASIC | ASIC | FPGA (Xilinx Vertex-II XC2V1000) |
| Encryption Algorithm | AES | MISTY | VSC (Vector Stream Cipher) |
| Features | * AES is the current standard selected by NIST, U.S.A. * Block Cipher | * KASUMI (a modified version of MISTY) is 3GPP Standard * Block Cipher | * The fastest encryption in the world * Full Scalable * Stream Cipher * Reconfigurable |
Such high-speed features of VSC come from full-scalable encryption algorithm as described as follows.
VECTOR STREAM CIPHER AS FULL-SCALABLE CHAOTIC ENCRYPTION
Our VSC is a kind of stream cipher. Thus, the main component of VSC is key generations.VSC uses a patented algorithm of generating random-vector generations based on skew product transformation [3]. Let f(p,x) be a transformation from n bit to n bit with 2n parameters p. Two-dimensional map composed from the skew product of f(p,x) is given by
y'=f(x,y)
z'=f(y',z).
z'=f(y',z).
Three-dimensional map composed from the successive skew products of f(p,x) is given by
y'=f(x,y)
z'=f(y',z).
w'=f(z',w).
z'=f(y',z).
w'=f(z',w).
We can generalize to arbitrary m dimensional map by using m-1 successive skew products of f(p,x). It is known in ergodic theory that if f(p,x) has the uniform invariant measure, the invariant measure of the skew product transformation is also uniform. We use this fact to generate arbitrary dimensional uniform random numbers. Such f('E,'E) can be constructed by
f(p,x) = 2x2+g(p)x mod 2n ,
where
g(p) =p-Mod(p,4)+3.
g(p) =p-Mod(p,4)+3.
Here, Mod(p,4) is defined as a residue of the devision of p by 4.
f(p,x) is known to be a permutation polynomial (one-to-one mapping over GF(2n)) whith any parameter p [4]. Because permutation polynomials have a uniform invariant measure, we can generate arbitrary many dimensional uniform distributions from skew product of permutation polynomials. It is noted that
if g(p) =1,
then f(p,x) is a permutation polynomial used in the well-known block cipher algorithm RC6 [5].
We combine this successive skew product transformations and bit rotation in our VSC. In this case, 1 bit difference on the initial data can give a global difference which can be measured by a large Hamming distance. Thus, this mappings over a finite field can be regarded as chaotic mappings over a finite field. Such chaotic dynamical system over a finite field have not been a subject of research to date. Thus, we can categorize a dynamics given by a polynomial mapping over the finite field into « digital chaos ». Our algorithm can be classified into a chaotic encryption algorithm based stream cipher. Thus, we call chaotic encryption algorithm VSC.
FULL SCALABILITY
We construct our IP core of VSC based on VHDL. Figure 1 clearly shows FPGA implemented scalability of VSC.
We use DDR-SDRAM Evaluation board (Tokyo Electron Device, Ltd.) with a FPGA (Xilinx Vertex II XC2V1000). If encryption speed is 200Mbps, gate size can be less than 10K, which is very efficient and suitable for implementing security in power limited mobile devices.
Table 2 shows more detail evaluation of implementation efficiency in FPGA when we use a Heron-FPGA board (Hunt Engineering, Ltd.) with the same FPGA. The VSC encryption speed data of Table 1 showing 25.62Gbps corresponds to the implementation of VSC 512 (512 bit key length) into the Heron-FGPA evaluation board in Table 2. In this experiments, implementation efficiency is always greater than 100 Kbps/Gate and less than 200 Kbps/Gate, which shows full-scalability and high implementation efficiency of VSC's IP.
'@'@'@
Figure 1'VSC's Scalability in FPGA Implementation'iKey Length'@vs Gate Size 'j
Table 2: VSC Implementation Result Based on Heron-FPGA Evaluation Board
| Type of Algorithm | Encryption Speed | Key Size | Clocks | Gate Size | Implementation Efficiency [Kbps/Gate] |
| VSC 1024 | 21.06 Gbps | 1024bit | 20.57MHz | 156,479 | 134.6 |
| VSC 512 | 25.62 Gbps | 512bit | 50.05MHz | 141,112 | 181.6 |
| VSC 256 | 12.88 Gbps | 256bit | 50.33MHz | 70,703 | 182.2 |
| VSC 128 | 7.033 Gbps | 128bit | 57.05MHz | 36,323 | 193.5 |
We also evaluate randomness property of VSC-generated bit sequences using the NIST Statistical Test Suite for Randomness called NIST 800-22 [7]. In 128bit key length encryption, VSC-based generated random numbers shows a better randomness property than AES and SHA-1-based generated random numbers. The detailed data is given in Ref. [8].
REALTIME HDTV ENCRYPTION
As an application of such high speed encryption, we develope a platform for realtime HDTV signal encryption for the first time. The schematic blockd diagram for realtime encryption system of HDTV signals is given in Fig. 2. In this system, we use our IP core of vector stream cipher as a cipher processor of HDTV. Since one HDTV signal transmission speed is 1.485 Giga bit/s, the total throughput for transmission speed is 14.85 Giga bit/s by generating 10 same HDTV signals as input data (PVin1 and PVin2) . This system encrypts HDTV data and decrypts encrypted data into the original HDTV data in realtime by using 14.85 Giga bit/s vector stream cipher processors implemented in Xilinx-Vertex II Pro. In the Ultrafast Data Processing Part in Fig. 2, we use the 10 serial data of 20bit size with a clock frequency 74.25MHz. Thus, we obtain the following formula for the speed
of encryption, decryption and transmission :
20bit × 74.25MHz × 10 (Parallel Series)'@= 14.85Giga bit/s.
Figure 2: Schematic Diagram for Encryption/Data Processing Function of HDTV Encryption System.
Since we use 8 series Rocket I/O for transmission of encrypted HDTV signals, the 10 to 8 transformation is used for encryption at the transmitter board and the 10 to 8 transformation is used for the decryption at the reciever board. The functional block diagram is given in Fig. 3. Here, IP core of vector stream cipher is implemented in the crl_scr_tx (t_crl) part. The clock frequency difference between the 74.25 MHz from the Data I/O board and
the 74.25 MHz generated by deviding the 148.5 MHz external OSC by two is adjusted in tx_fifo blocks.
Figure 3 : Block Diagram for Encryption/Data Processing Function of HDTV Encryption System.
Figure 4 : More Detailed Block Diagram for tx_fifo.
The tx_fifo block is shown in Fig. 4. Timing chart of this tx_fifo module is depicted in Fig. 5.
Figure 5 : Timing Chart for tx_fifo Block
Figure 6 : Realtime HDTV Encryption System with Half-Image Encrypted
Figure 7 : Realtime Bamboo-Blind Type HDTV Encryption System.
Since our encryption IP is implemented in FPGA, we can provide various type of encryption of HDTV. For example, a half-image HDTV encryption system is depicted in Fig. 6 and a bamboo-blind type HDTV encryption is depicted in Fig. 7 while those systems use the unique encryption/decryption processor. This shows that our vector stream cipher IP cores are implemented as reconfigurable encryption processors with retaining multi ten Giga bit/s processing speed.
CONCLUDING REMARKS
We introduce an IP core of high-speed stream cipher called VSC with some theoretical backgrounds and its applications to broadband security of HDTV encryption. VSC VHDL IP is shown to attain 25.6 Giga bit/s encryption speed in FPGA, which seems to the world record for encryption speed. While VSC can attain more speed in ASIC, VSC's implementation efficiency in FPGA is constantly very high which shows full scalable features of our IP. This IP core can be used for high-speed encryption as well as low-power encryption in mobile terminals. For demonstration purpose of showing such high-performance encryption, this IP core was used for the first experiment of real-time HDTV encryption, transmission and decryption at 14.85 Gbit/s which corresponds to the speed that 10 series of HDTV signals can be encrypted in real-time. The speed of 14.85 Gbit/s is also the fastest for encryption, transmission and decryption in the world to the author's knowledge [9]. Therefore, we conclude that our IP of VSC(vector stream cipher) is very suitable for realizing strong security of broadband networks such as 10Gbit/s IP networks of the near future.
ACKNOWLEDGEMENT
The author thanks Dr. T. Iida, Dr. K. Hasuike, and Dr. F. Kubota and Mr. F. Sawada of Communications Research Laboratory (CRL) for strong supports to this IP development and our making up a start-up company ChaosWare, Inc in CRL which can add potential market values to this IP core.
REFERENCES
[1] http://www.broadcom.com/products/5841.html
[2] http://www.security.melco.co.jp/SecWWW/category1/Japanese/MISTY1ipj.htm
[3] Introduction of Japanese Patent No. 3030341 (Inventor: K. Umeno)
http://www2.crl.go.jp/kk/e414/shuppan/kihou-journal/journal-vol49no3/05.pdf
[4]R. L. Rivest, Permutation Polynomials modulo 2^w, in Finite Fields and their Applications Volume 7 (2001), pages 287--292.
[5] ftp://ftp.rsasecurity.com/pub/rsalabs/rc6/rc6v11.pdf
[6]K. Umeno, « Scalable Chaotic Cipher and its Performance Evaluation of Hardware Implementation »,
The 5-th LSI IP Award Paper (2003, Nikkei Business Publishing, in Japanese).
http://ne.nikkeibp.co.jp/award/papers/2003_co02.pdf
[7] A Statistical Test Suite for Random and Pseudorandom Number Generators for Cryptographic Applications,
(October 2000, Revised May15 2001, NIST)
http://csrc.nist.gov/publications/nistpubs/800-22/sp-800-22-051501.pdf
[8]K. Umeno, S. Kim and A. Hasegawa, « The fastest cipher VSC : evaluation of its cryptographic randomness and implementation efficiency » (Lecture Note of invited talk at 21COE security seminar at Chuo-University,
April 16,2003)
http://www.21coe.chuo-u.ac.jp/security/umeno2003-04-16/umeno.pdf
[9] http://www2.crl.go.jp/pub/whatsnew/press/030415-1/030415-1.html