
Digitization can be implemented by converting the existing printed/typed data/documents into a digital format that is readable by the computer. Digital transformation creates greater processing efficiency and fewer risks of errors. It presents an opportunity to digitize business processes. The main objective of this article is to provide information regarding the digitization of data which is a key step in digital transformation. We will be discussing why, what, and how of OCR (Optical Character Recognition).
Why do we need OCR?
OCR or Optical Character Recognition is used to read text from images and converting them into text data for digital content management across many industries. It is mainly used as a substitute for data entry and also for information gathering, analysis purposes, and various other purposes.
At the start of the digital revolution, when most of the printed information was being uploaded on the web, manual data entry of such humongous printed data (like those of newspaper collections) became a task that required time and patience. This data entry task was also prone to human errors. The outcome of this problem was in the form of the birth of OCR. It was invented in the early eighties. OCR is now mature enough to grab characters and words from images to extract meaningful information. This technology has now attained a near-perfect text detection accuracy.
Here are some benefits of Digitization of physical data:
- Increased Security: Physical documents cannot be tracked but scanned documents can be tracked. The access to the digitized documents can also be restricted.
- Saves Space: Digital storage spaces are way cheaper to take on rent than physical spaces. Eliminating the need for paper storage can help save more space, thereby reducing the requirement of physical space.
- Risk Mitigation: In case of a natural or manmade disaster, the risk of losing physical documents is mitigated by digitizing them.
- Ease of access: Digitized documents can be easily accessed as compared to physical ones. The search for a physical document in storage takes way more time than the search for a digitized document on a digital storage device or network.
- Cost Efficiency: The cost of producing digital documents is fractional compared to the humongous cost of paper, printer, ink, storage all put together.
- Ease of data search: Ease of data search inside a bunch of documents is possible in case of digitized documents but one has to physically examine each physical document to search particular data. Digitizing documents can save tons of time.
- Environment Friendly: Digitizing documents saves paper, ink(chemicals), etc., saving the a lot of energy resources..
- Data Sharing: Easier and quicker data sharing is possible in the case of digitized data but not in case of physical data.
Each and every company will, sooner or later will be faced with a need for digitization. Let us see some of the useful use cases of OCR.
OCR Use Cases
There can be many use cases (previously unheard of) for OCR. Here are some that are definitely possible in the near future as technology enhances:
- Automatic vehicle number plate recognition is an already existing technology, developed using OCR. The images of vehicle number plates captured using CCTVs are used to catch guilty culprits without human intervention. This helps in automating traffic rule enforcement.
- OCR can be extremely helpful for professionals dealing with humongous amounts of data like the Medical, Legal professionals. This can be achieved by extracting all the medical or legal information like case histories and other details from the printed documents by scanning them and then applying OCR to digitize the data for storage and eventually organizing the contents to create an in-house search engine to search information from the database or content management system.
- OCR can help in automating the data entry processes. Instead of manual keying of data, one can use OCR to read data from images and documents and store them in a database or use it to upload it on to the web. This avoids errors introduced due to manual data entry processes by us humans. Some existing use cases of automating data entry include reading data from blood, urine, and various other health reports. Reading data from medical forms, insurance claims, or health reports for data analysis. One can also apply the latest machine learning algorithms and techniques to get meaningful insights from such data for medical, insurance, or health prediction. Extracting data from loan applications, form submissions, web scraping (extracting data from websites), etc.
- OCR can also be used for assisting blind and visually impaired people by scanning the printed data using OCR and reading it aloud using text reading technology.
- Data detection and recognition in self-driving vehicles. A camera inside a vehicle can read road signs and detect meaningful data from the images using OCR to automating the drive of a self-driving vehicle. Object detection can be used to detect objects to avoid accidents.
- Passport/VISA/Ticket recognition at Airport counters.
- Manage mismatches in Auditing.
- OCR can also be used for Language understanding and translation. Language translator computer applications can be developed using OCR, by scanning a business card/ image or a document in any language and interpreting the data in a preferred language. This can be helpful for tourists and business communities to interact with the local populace of any country.
- Creating a paperless office is the need of the day considering the rising real estate prices. This can be achieved using OCR. The amount of digital data stored on a USB stick can suffice for the physical storage space of a whole building, thus reducing the real estate costs for a company and also saving time to search a specific set of information in the data using content management systems.
How OCR Works?
OCR technology is used to convert images containing written text (typed, handwritten, or printed) into machine-readable text data. It is widely used as a form of data reading/entry/update from printed records.
- Data reading through OCR requires three stages. Initially, some pre-processing is applied to the image which includes line removal, segmentation, de-skewing, decoloring, etc. These methods ensure the accuracy of the data that is read.
- Once the pre-processing is done, either Pattern Matching or Feature Extraction, are used to start the conversion process. Pattern matching makes use of stored glyphs that are equated to the data of the image being converted. This method is largely dependent on the font type and size and works best for images containing traditional fonts.
- In Feature Extraction, the stored glyphs are broken down and are then used for accurate differentiation between the image’s characters. Once the pattern matching/feature extraction is done, some more post-processing is applied to ensure the highest level of accuracy in the converted text.
The OCR sub-processes are as follows:
- Pre-processing of the image
- Text Localization
- Character Segmentation
- Character recognition
- Post-Processing
There are numerous tools available for OCR processing, let us see some of the freeware and commercial tools.
OCR Tools
Tesseract (Freeware)
Tesseract is an open-source OCR Engine. It is a freeware available under the Apache License. It is one of the top few free OCR Engines available today. The latest version(v4) of OCR (available in GitHub) uses artificial intelligence for text recognition. It internally uses the LSTM (Long Short Term Memory) algorithm, which is based on Neural Networks logic. It currently supports the recognition of the scripts of more than 100 languages.
Tesseract has API interfaces for C++, Python, etc. and can be executed from the command line interface as well.
Installing Tesseract
Installing Tesseract on Windows is easy with the precompiled binaries. (https://github.com/tesseract-ocr/)
After the installation verify that everything is working by typing command in the terminal or cmd:
$ tesseract –version
And you will see an output similar to:
tesseract 4.0.0
leptonica-1.76.0
libjpeg 9c : libpng 1.6.34 : libtiff 4.0.9 : zlib 1.2.8
Found AVX2
Found AVX
Found SSE
You can install the python wrapper for tesseract after this using pip.
$ pip install pytesseract
The command-line tool is also called a tesseract. We can use pytesseract to execute OCR on images. The output of the process is then stored in a text file. Pytesseract is a wrapper for the Tesseract-OCR Engine.
To integrate Tesseract in Python code, we will use Tesseract’s API (Pytesseract ).
Tesseract is generally used with OpenCV (Open source Computer Vision Library) and Pytesseract (Python wrapper for tesseract OCR Engine)
Using Tesseract for digitizing data

If the image is modified to a minimum of 300x300 dpi then the reading of the image becomes easier.
The ‘image_to_string()’ and the ‘image_to_data()’ functions work well if the size of the smallest letter in the image is at least 20 units in height.
The ‘image_to_data()’ function contains a column that displays the height of each character/word that is read. If the character/word size is too small or too large then the image size needs to be decreased or increased to get the median word size somewhere near 20 for getting accurate text data from the image.
The term ‘median’ is used here and not average because, the image might contain extreme word sizes depending on whether the image carries a logo containing the name of the company in large font or something like “*conditions apply” in a small, nearly unreadable font.
The code to resize the image is as follows:

.
Note: Some amount of image processing may also be required for getting the best out of tesseract. We may have to remove noise, apply, Brightness/Contrast, De-Color the image, or De-Skew the image depending on the type of images provided.
One might also need Edge-Detection Algorithms for detecting the edges of the words or characters for the tesseract to decipher the image more accurately. All these image processing mechanisms come under different segments and thus haven’t been discussed here. The OpenCV library provides us with the API’s to all the image processing algorithms mentioned above.
Challenges for block/column-based data
Tesseract is not always able to read text across columns or blocks. It will always try to join text across blocks/columns placed way apart. If the image is skewed or contains discontinuous text (two words at a distance with a big blank space in between) or different words with different font and font sizes, as seen on bills or medical reports, where the company/hospital name is printed in a bigger font than the content of the bill or report, then the data obtained from the ‘image_to_string()’ function is unaligned and jumbled up.
Solution:
- In such a cases, the trick is to use both ‘image_to_string()’ function and ‘image_to_data()’ function to get the correct data.
- The trick is to use the top and left co-ordinates from the ‘image_to_data()’ matrix and match it with the first few words of the ‘image_to_string()’ output and then adapt the sentence in the ‘image_to_string()’ calls based on the top values of words in the ‘image_to_data()’ output.
- This little trick helps us solve the jumbling of data a few cases where the image contains blank columns.
Page Segmentation Modes in Tesseract
The Tesseract provides several modes to run OCR only on small regions/blocks or various orientations. The Command-Line argument ‘--psm’ is used to decide the page segmentation mode.
A list of the PSM (Page Segmentation Modes) supported by tesseract -
- Orientation and Script Detection (OSD).
- Automatic page segmentation with Orientation and Script Detection(OSD).
- Automatic page segmentation, but no OSD, or OCR.
- Fully automatic page segmentation, but no OSD. (This is the default mode)
- Assuming a single column of text of variable sizes.
- Assuming a single uniform block of vertically aligned text.
- Assuming a single uniform block of text.
- The image being treated as a single text line.
- The image being treated as a single word.
- Treating the image as a single word in a circle.
- Treating the image as a single character.
- Sparse text. Find all the possible text in no particular order.
- Sparse text with OSD.
- Raw line. Treat the image as a single text line
Limitations of Tesseract
- Since this is a freeware, it is not as accurate as some commercial solutions (Amazon Rekognition, Google Vision API) that are currently available in the markets.
- The accuracy of handwriting recognition is very low, almost unacceptable for most handwriting types.
- If the size of the noise is high, it may recognize the noise content as some ASCII characters.
- It may fail to read images with a lot of artifacts.
- It fails to read words/characters with lines crossed across them like in many bills or reports.
- Tesseract is not always able to read text across columns or blocks. It will always try to join text across blocks/columns placed way apart. The trick to resolve this issue is given above.[ST3]
- If the character/word size is smaller than 10 pixels, then the accuracy of the letters/words recognized will be low.
- Dark-colored images are difficult to interpret.
Google Vision API (Commercial)
This is one of the most popular ‘cloud-based’ tools that are available today and it gets the most accurate information. The Google Vision has a lot more to it than OCR. It’s more of an image processing framework. Besides OCR it also provides Logo Detection, Landmark Detection, Object Detection, Face Detection, Sentiment Detection, Image search, Nudity Detection, Violence Detection, etc
The sample Python code for Text Detection (OCR) is shown below:

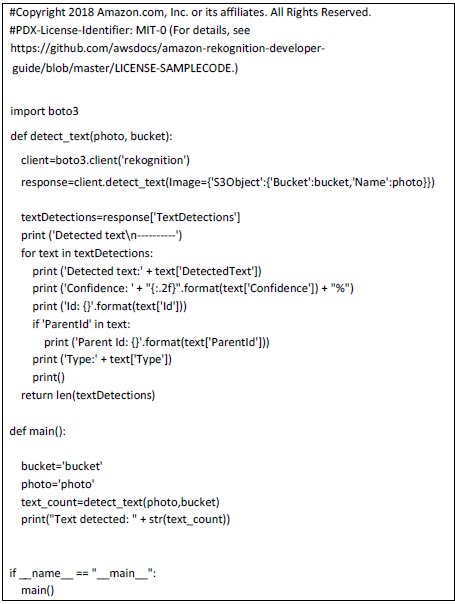
Amazon Rekognition (Commercial)
It is again a ‘cloud-based’ image processing framework just like Google’s Vision API. The Amazon Rekognition framework uses deep learning technology to key out objects, images, and faces as well. This tool is less expensive than Google Vision. Besides OCR it also provides Object Detection, Face Detection, Sentiment Detection, Image search, Face Search, Face comparison, etc.
The sample Python code for Text Detection (OCR) is shown below:
Conclusion
OCR is found to be a remarkable piece of technology and in this article, we have discussed why we need OCR, how it works, its uses cases, advantages, and processing tools. This article can be considered as a starting point for the idea of digitization for business communities. Using a combination of new technologies like machine learning and NLP, along with OCR can provide us with ample ideas and opportunities to come up with new products for the betterment of mankind and nature.
eInfochips’ Artificial Intelligence & Machine Learning offerings help organizations build highly-customized solutions running on advanced machine learning algorithms. We also help companies integrate these algorithms with image & video analytics, as well as with emerging technologies such as augmented reality & virtual reality to deliver utmost customer satisfaction and gain a competitive edge over others. For more information contact us today.
References:
- https://github.com/tesseract-ocr/
- https://en.wikipedia.org/wiki/Tesseract_(software)
- https://opensource.google/projects/tesseract
- https://nanonets.com/blog/ocr-with-tesseract/
- https://medium.com/@balaajip/optical-character-recognition-99aba2dad314
- https://docs.aws.amazon.com/rekognition/latest/dg/text-detecting-text-procedure.html